Chapter 29 Latent Variable Modeling – Path, SEM, CFA
Material in this chapter is directly lifted from Latent Variable Modeling Using R.
29.1 Path Analysis
29.1.1 Background
29.1.1.1 Basic Representation
Beau
A path model is a graphic representation of what we are trying to model. In a path model, there are two types of variables
- Exogenous : without direct cause AKA IVs
- Endogenous: with direct cause AKA DVs
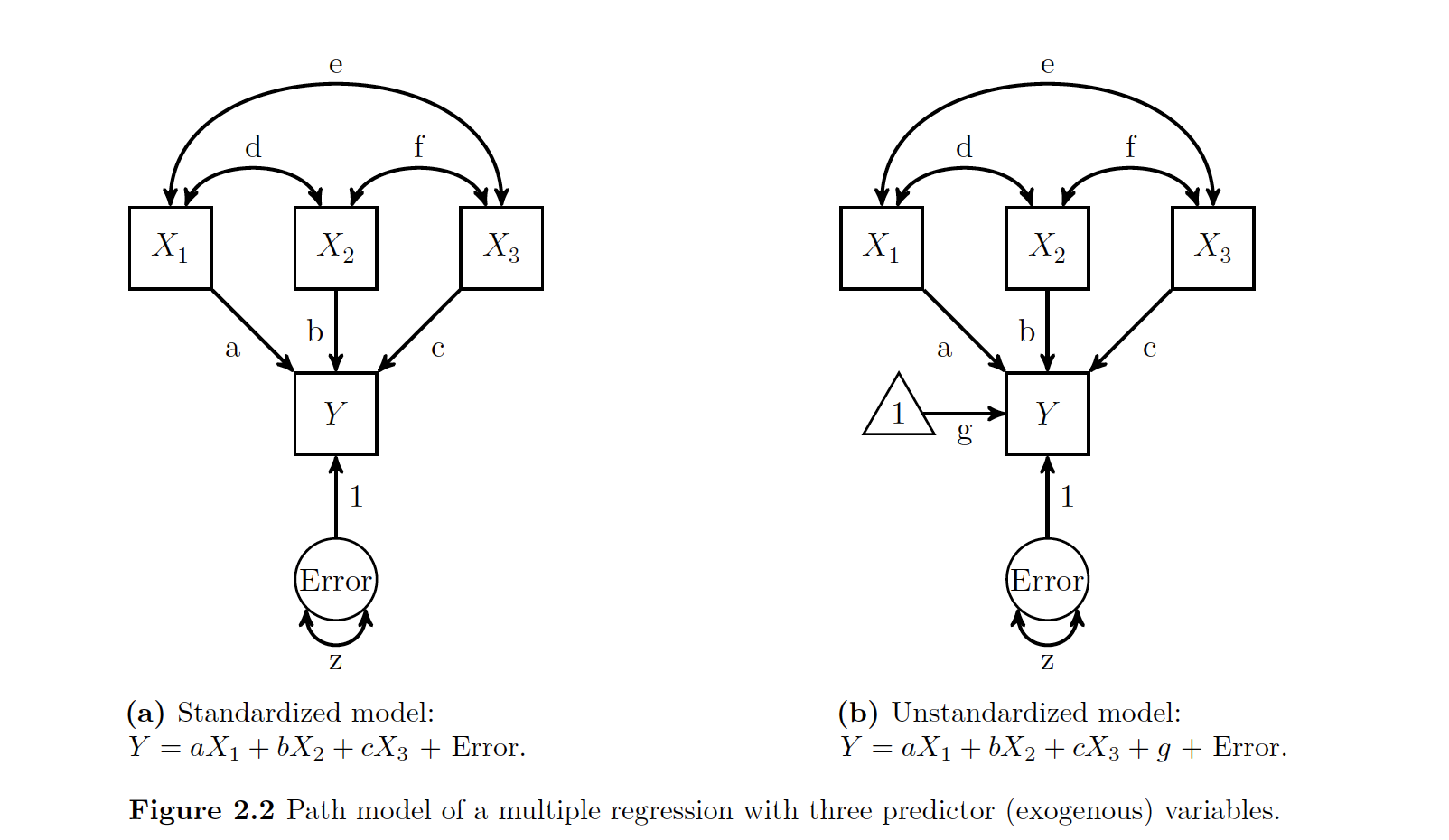
In the figure below, the Xs are exogenous and the Ys are endogenous
Beau
If a an arrow has a single head, it means it is causing a relationship. If there is a double headed arrow, it means that the relationship is a correlation and there is some sort of covariance.
All important relationships are assumed to be present in a path model. If you do not show the relationship, it is assumed not to exist.
Our predicted value, or endogenous variable, or Y, always has an error term with it. Just like you would imagine with any other type of model.
Note that your error terms with the predicted or endogenous variables are never connected to bi-directional arrows. Their error terms on the other hand, can be! This is important because sometimes your error terms will share a certain amount of co-variation. This is indicated by having the double arrow on either side of the errors. The author shows that in a figure like the one below.
Beau
As seen above, we use the coefficient c to talk bout the relationship between two variables (in this case, X and Y) after removing the effect of W.
What we are doing now as we depart from things like regression analysis, is look at things beyond manifest variables (things you can see like height or age and get a good number on) and move towards looking at latent variables. We can’t directly observe latent variables, but we assume for them to be there.
You will sometimes seen path diagrams displayed differently, but as far as this book is concerned, all relationships will be made explicit in the path diagram.
29.1.1.2 Tracing Rules
Sewall Wright was a genetecist who came up with the rules on how to derive our values for path analysis. What we are doing is estimating the coovariance between two variables by summing the appropriate connecting paths. If you have a basic model (no means ELABORATE HERE LATER WHEN YOU GET IT!), there are only a few rules
- Trace all paths between two variables (or a variable back to itself), multiplying all the coeffecients along a given path
- You can start by going backwards along a single (directional!) arrow head, but once you start going forward along these arrows you can no longer go backwards.
- No loops! You can not go through the same variable once for a given path.
- At maximum, there can be one double sided arrow in a path.
- After tracing all paths for a given relationship, sum all the paths
The basic idea with these rules is that you need to look at each variable and try to get from your exogenous (IV) to your endogenous (DV) every way you can, without breaking the rules. So to get from your first X1 to Y, you can either go
- Directly there via a
- Jump over via e, then through X3 to C to Y1
- Jump over via d, then through b
- This results in saying from \(X1\) to \(Y\), notated 0_1Y = a + ec + db
- You then do this for the other exogenous variables
Note that we also have to consider the covariance of Y with itself. Since we can go backwards on a one directional arrow, we can go back to X1 via a, but then have to go back (Why?!) and the same for z, our residual. Then if we add all three up, we get the amount of our endogenous variable’s variance explained by in X1, X2, X3 (the \(R^2\)) and z is what is left over. IS THIS KIND OF LIKE A SUM OF SQUARES TOTAL VARIANCE?!
29.1.2 Getting Numeric
So now we know how these things work, what we then want to do is see what happens when we look at putting numbers inside of them. * Step 1: Look at the correlations (double headed arrows) that we know from our correlation matrix * Step 2: Do clever algebra knowing you have three values and three related equations to derive your missing values. SO FUCKING COOL! * Step 3: Now you know all the path values, you just need to figure out the residual. * Step 4: See the book for the exact math of it
29.1.2.1 Path Coeffecients
So the values with the double arrow heads we know are correlation coeffecients. But those are not the same as single arrow heads! These single headed arrow values are standardized partial regression coeffecients or path coeffecients. Note the two important parts of this definitions: standardized and partial. Standardized means it refers to values on z scores. Partial means they are values for after the effects of other variables have been controlled for.
Note that this is just like regression standard vs unstandardized in that you can convert standardized to non. The same benefits apply (intra model comparision vs interpretability).
29.1.3 Doing It in R
To do path modeling in R, this book will use the lavaan package.
Note lavaan means ‘’LAtenent VAriable ANalysis’’.
To make a latent variable model in R, you need to specify two things
- Specify the path model
- Analyze!
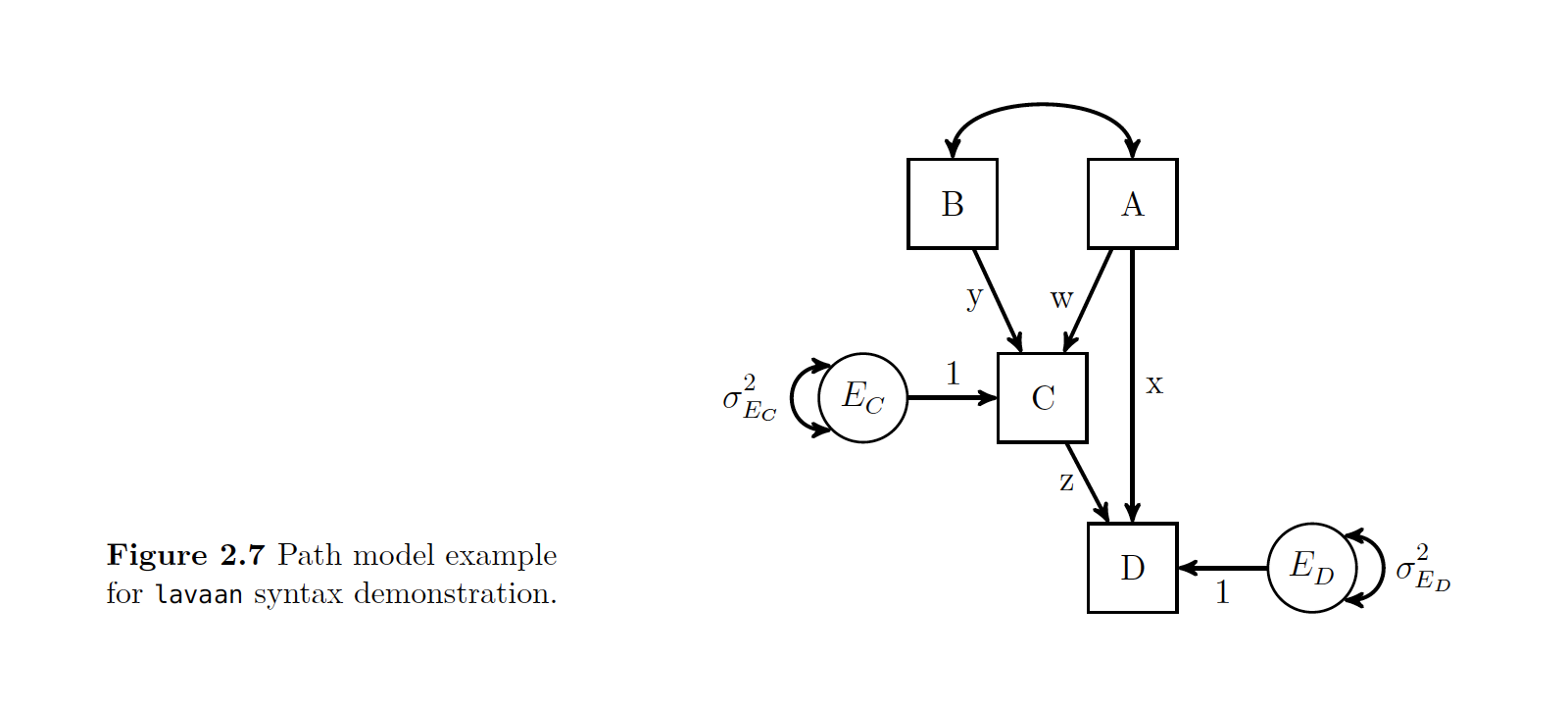
Take a second and look at the given R syntax and the path model that it is showing. The author walks us through this…
Note the top line is the model definition and you have to put it as a string see the ’ ! We then put C and D as outcomes with their associated paths.
beat
## This is lavaan 0.5-23.1097## lavaan is BETA software! Please report any bugs.##
## Attaching package: 'lavaan'## The following object is masked from 'package:psych':
##
## cor2cov example.model <- '
C ~ y*B + w*A
D ~ z*C + x*A
#Optional Label of Residual Variance
C~~C_Resid*C
#Optional Label of Residual Variance
D~~D_Resid*D
' Once you set this model, then you can do either a cfa() or sem() call to the model.
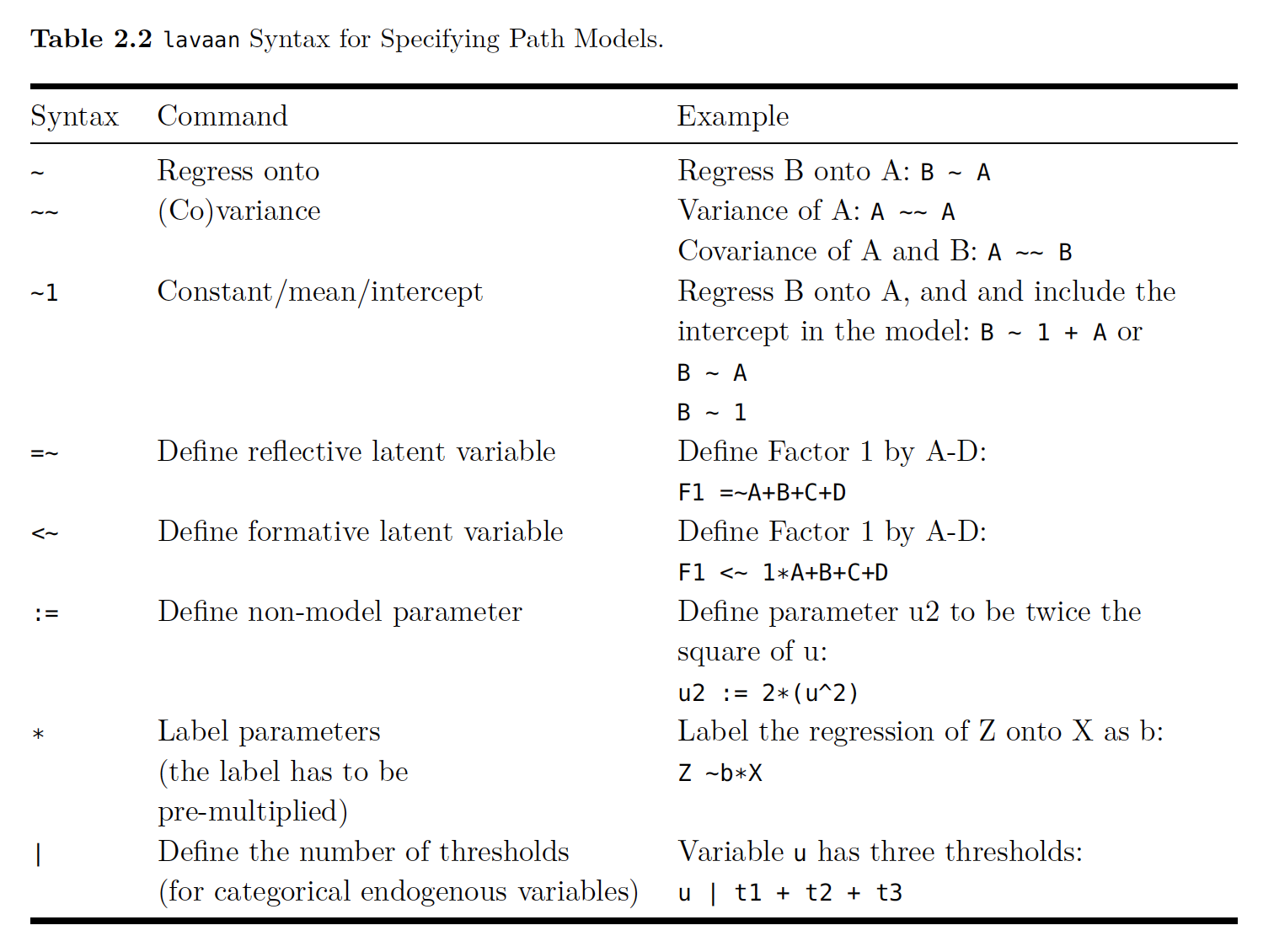
Below is a cheat sheet for lavaan’s syntax:
Path
29.1.3.1 More Syntax
You can enter either the raw data, or the covariance matrix in R with lavaan.
- Raw data = data argument
- Covariance Matrix = sample.cov, with this you also get option for input a mean vector with sample.mean()
example.fit <- sem(example.model, data=example.data)
example.fit <- sem(example.model, sample.cov = example.cov, sample.nobs =500)The default option with lavaan is normal-theory maximum likelihood.
Once you designate a model using either the syntax
Then you just (like everything in R) need to call the summary function on it. With the summary() function you get
- Note if parameter estimations converged
- Sample Size
- Estimator
- fit statistic with df and p value
- Unstandardized parameter values
- The parameter estimates’ standard error
- The ratio of parameter estimates and their standard errors (Wald statistic)
- P value for Wald statistic
You can change the arguments if you want to get other types of values for the model.
29.1.4 An Example In R
#--------------------------------------------------
## Make Data
regression.cor <- lav_matrix_lower2full(c(1,.2,1,.24,.3,1,.7,.8,.3,1))
colnames(regression.cor) <- row.names(regression.cor) <- c("X1","X2","X3","Y")
regression.cor## X1 X2 X3 Y
## X1 1.00 0.2 0.24 0.7
## X2 0.20 1.0 0.30 0.8
## X3 0.24 0.3 1.00 0.3
## Y 0.70 0.8 0.30 1.0## Specifiy Path Model
regression.model <- '
#Structural Model for Y
Y ~ a*X1 + b*X2 + c*X3
#Label Residual Variance for Y
Y ~~ z*Y
'
## Estimate Parameters with sem() and n = 1000
regression.fit <- sem(regression.model, sample.cov = regression.cor, sample.nobs = 1000)
summary(regression.fit, rsquare=TRUE)## lavaan (0.5-23.1097) converged normally after 25 iterations
##
## Number of observations 1000
##
## Estimator ML
## Minimum Function Test Statistic 0.000
## Degrees of freedom 0
## Minimum Function Value 0.0000000000000
##
## Parameter Estimates:
##
## Information Expected
## Standard Errors Standard
##
## Regressions:
## Estimate Std.Err z-value P(>|z|)
## Y ~
## X1 (a) 0.571 0.008 74.539 0.000
## X2 (b) 0.700 0.008 89.724 0.000
## X3 (c) -0.047 0.008 -5.980 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Y (z) 0.054 0.002 22.361 0.000
##
## R-Square:
## Estimate
## Y 0.94629.1.5 Indirect Effects
The examples above are concerned with one variables direct effect on another. An an indirect effect is an effect a variable has on another variable when going through one other variable.
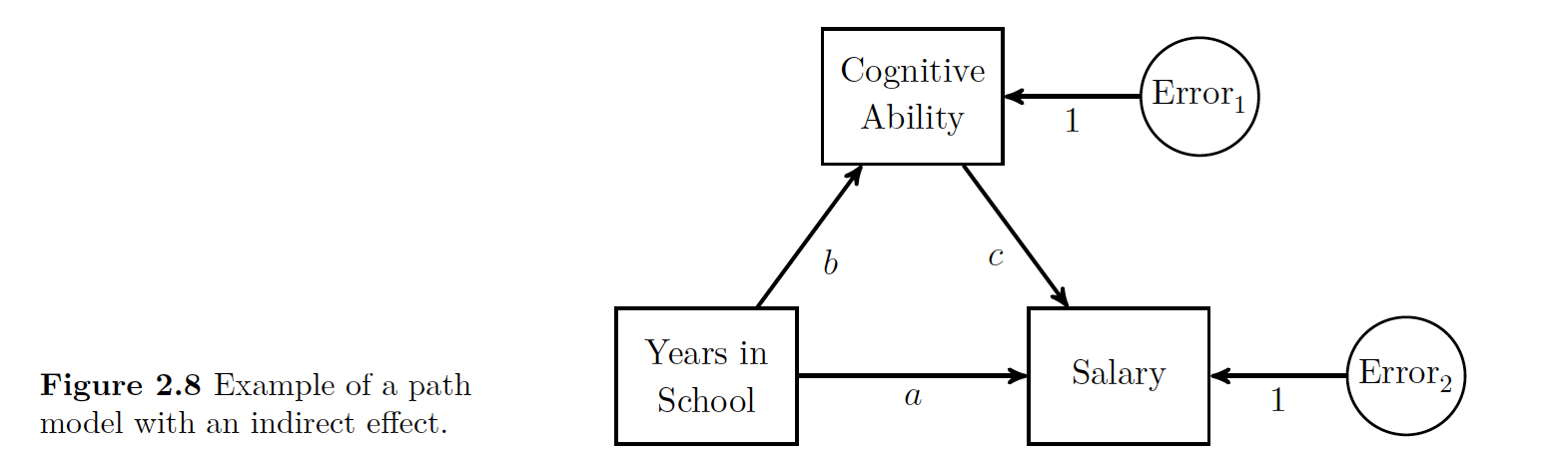
Here we have an example of an indirect effect. The figure show that years in school directly affects salary as shown with the direct arrow path ‘’a’‘. The model also supposes that cognitive ability can indirectly affect salary, but cognitive ability is affected by number of years in school. The indirect influence is a compound effect. You can use the tracing rules to see that it’s possible to go via’‘b’’ and ‘’c’’ to get to salary.
29.1.5.1 Example with Indirect Effects
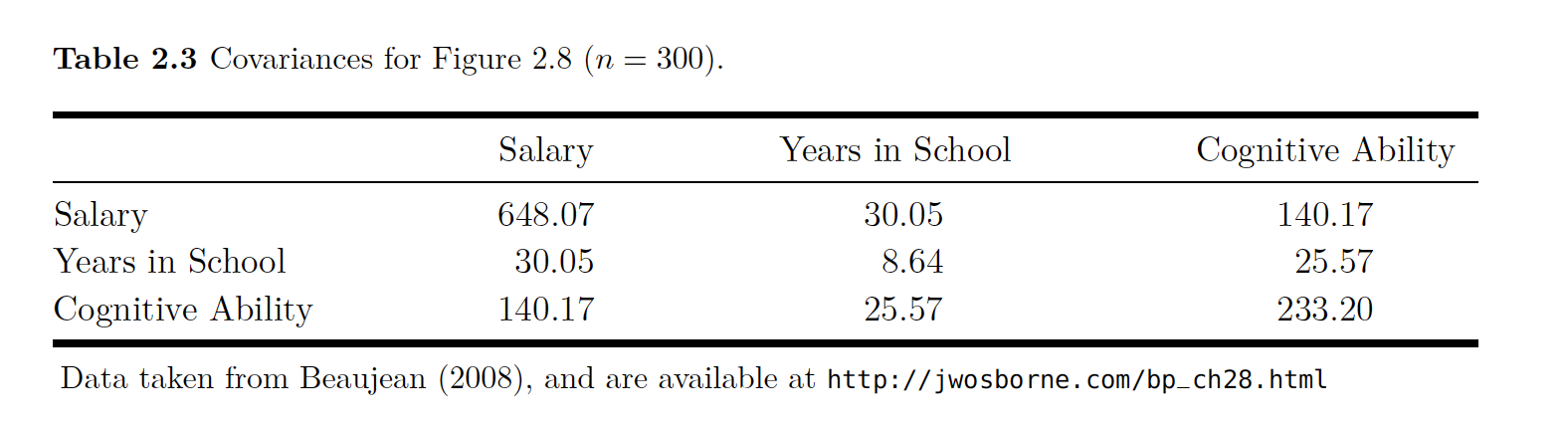
The data to estimate this model are given here with the parameter values and the covariances.
beau
All of this data is put together and analyzed in the code below.
beau
# Indirect Model
# Make Data
beaujean.cov <- lav_matrix_lower2full(c(648.07,30.05,8.64,140.18,25.57,233.21))
colnames(beaujean.cov) <- row.names(beaujean.cov) <- c("salary","school","iq")
beaujean.cov## salary school iq
## salary 648.07 30.05 140.18
## school 30.05 8.64 25.57
## iq 140.18 25.57 233.21# Specifiy Path Model
beaujean.model <- '
salary ~ a*school + c*iq
school ~ b*iq
ind:= b*c
'
# Estimate Parameters
beaujean.fit <- sem(beaujean.model, sample.cov = beaujean.cov, sample.nobs = 300)
summary(beaujean.fit)## lavaan (0.5-23.1097) converged normally after 23 iterations
##
## Number of observations 300
##
## Estimator ML
## Minimum Function Test Statistic 0.000
## Degrees of freedom 0
## Minimum Function Value 0.0000000000000
##
## Parameter Estimates:
##
## Information Expected
## Standard Errors Standard
##
## Regressions:
## Estimate Std.Err z-value P(>|z|)
## salary ~
## school (a) 2.515 0.549 4.585 0.000
## iq (c) 0.325 0.106 3.081 0.002
## school ~
## iq (b) 0.110 0.009 12.005 0.000
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .salary 525.129 42.877 12.247 0.000
## .school 5.817 0.475 12.247 0.000
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|)
## ind 0.036 0.012 2.984 0.003## Reporting results
library(xtable)
xtable(parameterEstimates(regression.fit, standardized = TRUE)[,c(1:3,5:6,12)], caption="Example Table Using \\texttt{xtable()} Function.")## % latex table generated in R 3.4.1 by xtable 1.8-2 package
## % Thu Sep 20 15:52:18 2018
## \begin{table}[ht]
## \centering
## \begin{tabular}{rlllrrr}
## \hline
## & lhs & op & rhs & est & se & std.all \\
## \hline
## 1 & Y & \~{} & X1 & 0.57 & 0.01 & 0.57 \\
## 2 & Y & \~{} & X2 & 0.70 & 0.01 & 0.70 \\
## 3 & Y & \~{} & X3 & -0.05 & 0.01 & -0.05 \\
## 4 & Y & \~{}\~{} & Y & 0.05 & 0.00 & 0.05 \\
## 5 & X1 & \~{}\~{} & X1 & 1.00 & 0.00 & 1.00 \\
## 6 & X1 & \~{}\~{} & X2 & 0.20 & 0.00 & 0.20 \\
## 7 & X1 & \~{}\~{} & X3 & 0.24 & 0.00 & 0.24 \\
## 8 & X2 & \~{}\~{} & X2 & 1.00 & 0.00 & 1.00 \\
## 9 & X2 & \~{}\~{} & X3 & 0.30 & 0.00 & 0.30 \\
## 10 & X3 & \~{}\~{} & X3 & 1.00 & 0.00 & 1.00 \\
## \hline
## \end{tabular}
## \caption{Example Table Using \texttt{xtable()} Function.}
## \end{table}29.2 Basic Latent Variable Models , SEM
29.2.1 Background
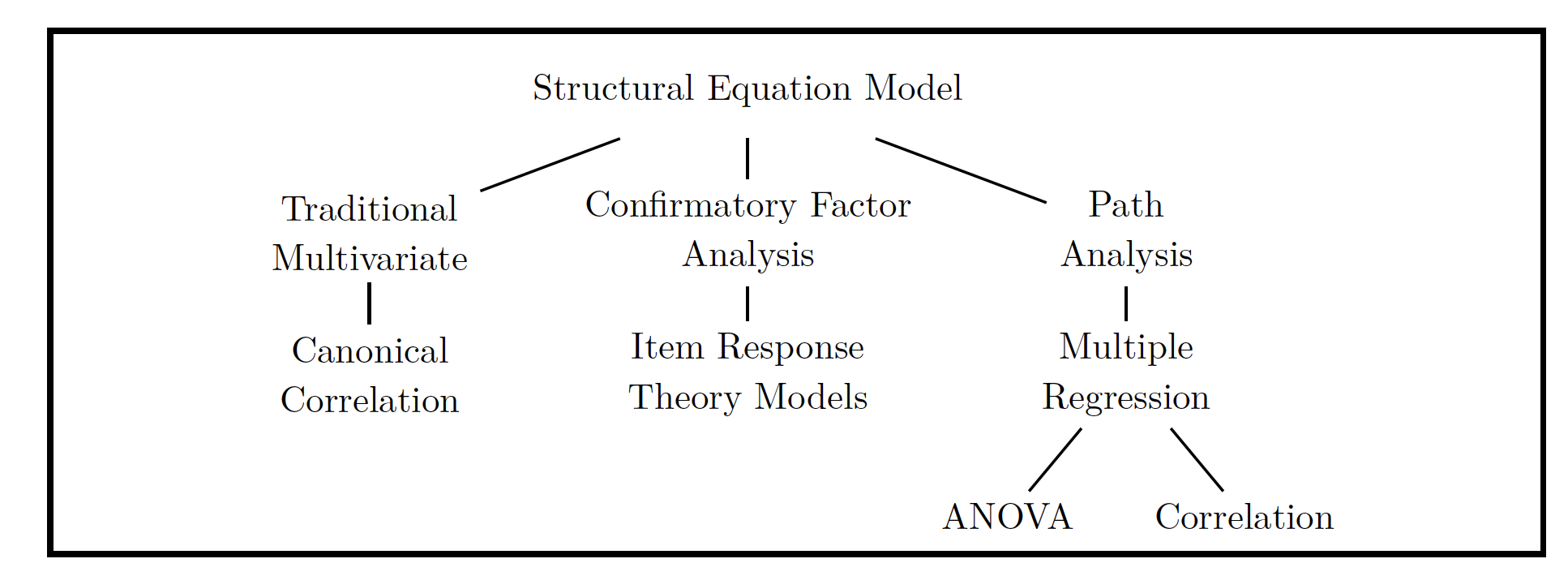
The big umbrella term for the statistical models that use a structural model and a latent variable model are structural equation models’’ or SEMs.
Reiterating for my own sake, we have two main parts * The Structural Model: Regression-like relationship between variables * The Latent Variable Model: Creates the latent variable structure
If there is latent variable model is analyzed without a structural model it is often called Confirmatory Factor Analysis or CFA. If you don’t even have a hypothesized latent variable structure, then you have Exploratory Factor Analysis’’’ or EFA. Note that when we say factor in factor analysis, that is synonymous with the idea of latent variable. The way in which all of the variables relate to one another can be seen in the chart below.
img
29.2.2 Latent Variable Models
img
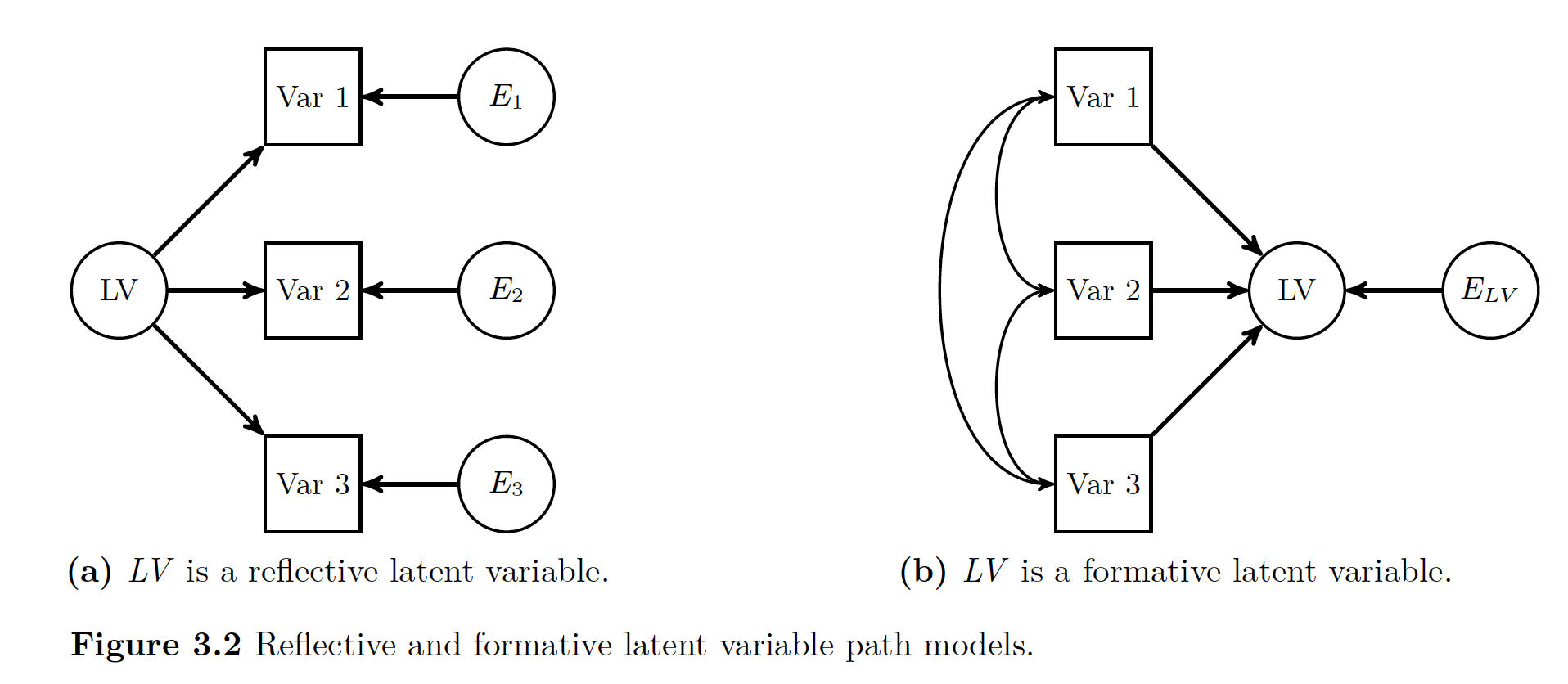
There are two types of latent variables * Reflective: Thought to cause other variables to covary * Formative: Are result of other variables’ covariation (like regression)
This book/wiki will focus primarily on reflective (variables cause others to covary). The point of using a reflective model is to understand the structure that caused the manifest variables to act like they do. These manifest variables that have an effect on the latent variables are also called indicator variables. The idea behind the whole thing is that there is a variable latent (badumch) driving the way that each indicator variable acts.
In the chapter before we had a latent variable, but it was the error term. In the whole mess of numbers the LV was an unobserved value that had a significant amount of influence one of the observed variables. But since it was an error term, it was technically measured differently than how we normally go about measuring LVs.
The big idea behind LVM is that behind the one big thing you are measuring, there are a few small LVs that you can observe at an individual level.
First have a peek at the idea behind g, or intelligence.
We see the big thing g at the top of it, and five MV (manifest variables) or indicator variables.
Based on how the indicator variables interact, we can have an idea of what is going on with g.
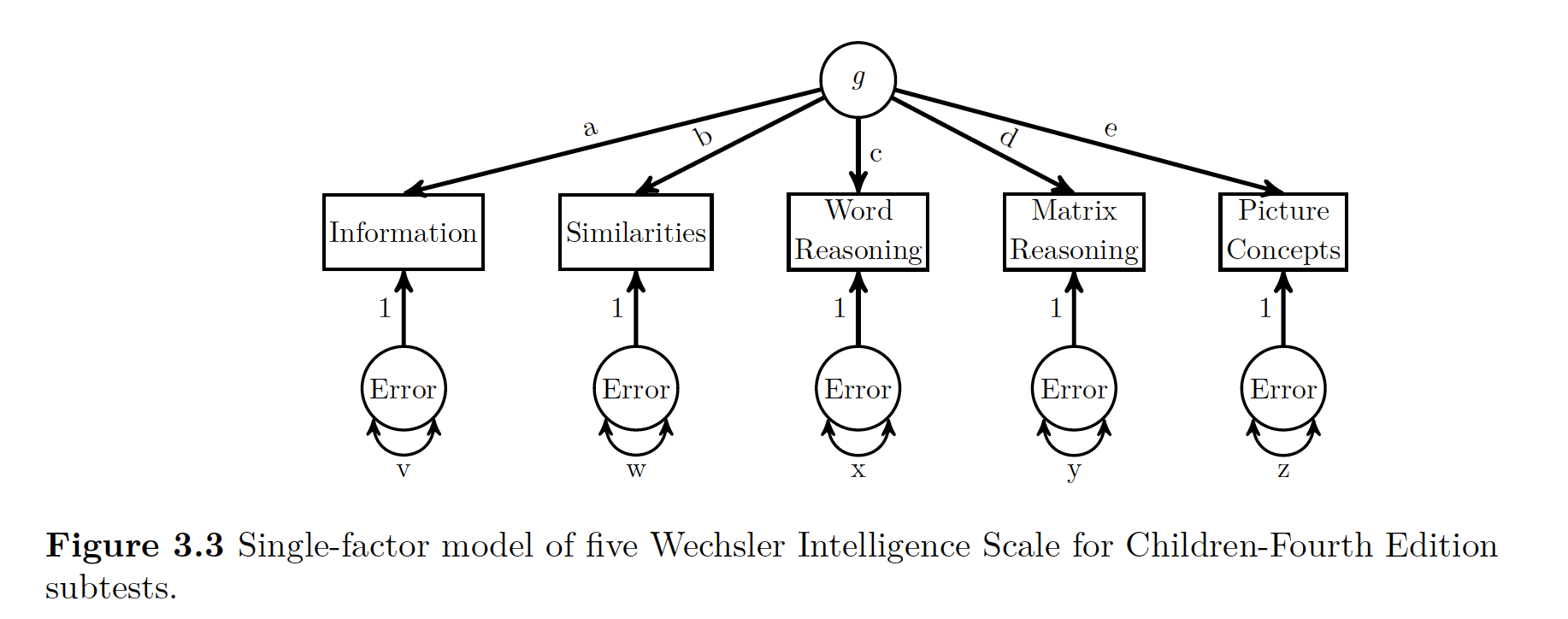
beau
**So the idea with LV modeling is that a way to identify or confirm the number of LVs that are producing the manifest variables to act the way they are*.**
One measure of influence that the latent variable has on the manifest variables is the factor loading. You can think of these factor loadings like regression or path coefficients. There is another term called structure coefficient’’. A structure coefficient is the correlation between the model’s MV and the LV. Now if you only have one LV, like the figure above, these are the same things. If you have more than one LV, these are different (unless somehow all your values are not correlated with each other).
If you look above again at the figure all a, b,c, d, and e are factor loadings. They show the relationship between the LV and the MV.
Now being super clever again, you can get something kind of like an \(R^2\) value for for each MV using the path rules described in the previous chapter. That R^2-y value is the communality of the variable. The opposite of communality is uniqueness. Uniqueness is the amount of of variance in the MV not accounted for by the LV.
A good example to demonstrate this is by looking at the Information manifest variable above. Since you are intersted in that variable, you can go up the path to g via a, then since you can’t go anywhere else (no double headed arrows), then you can slide back down a, follow the rules that you have to multiple your paths, and then that value of a x a is the amount of variance in g explained in information.
29.2.2.1 Identification of Latent Variable Models
LV modeling questions come down to one big question: > Is there enough non-redundant information in the data to be able to estimate the required parameters uniquely?
This is not a problem with regression models because the number of parameters to estimate exactly equals the amount of non-redundant information. If that is confusing (it was to me the first time), then just think that the amount of non-redundant information in the data as the number of non-redudant variances/covariances in the dataset.
We run into a bit of a problem with LVM because models can be 1. Just identified 2. Underidentified: more parameter to estimate than non-redudant information, creates error messages with lavaan 3. Overidentified: More MVs than you need to get at the LVs that are there, does create model fit
Degrees of freedom in LVM are the number of non-redundant pieces of information in the data subtract the amount of parameters to estimate.
The following is a list of rules of thumbs to get you to a good model, since hitting it right on the head is really hard.
29.2.2.1.1 Number of Indicator Variables
The big goal is to have at least 4 indicator variables for each latent variable in the model, hoping desperately that none of their error variance covary.
Even if you don’t have that, you can hope for at least 4 conditions as long as you get one of these.
- At least 3 indicator variables with no error covariance
- The LV has at least 2 indicators with non-covarying error variances and the indicator’s variables’ loadings are set equal to each other
- The LV has one indicator, the directional paths are set to one, and the error variance is fixed to some value
- The fixed value is either 0.0 meaning indicator variables has perfect reliability OR
- Something about reliability and variances <— DON’T GET THIS!!
29.2.2.1.2 Latent Variable Scales
Since LVs are not observable, they are measured an abstract scale. Because of this, the numbers we use to measure things is constrained by setting one of the parameter estimates. Normally we set one of these parameter values one of three ways 1. Standardized Latent Variable: Put LV’s variance to 1, if you then standardize indicator variables, interpret all like regression 2. Marker Variable: Single Factor loading for each LV constrained to arbitrary value , the one that is set to 1 is the marker variable 3. Effects Coding: Estimates all loadings, constrains number of loadings for given LV to 1
29.2.2.1.3 Other Conditions
- If you have more than one LV in model… for each PAIR of the LVs
- Each LV needs one indicator variable that has no error co-variance with other LVs (solely responsible for variance in LV?)
- Covariance of Pairs of LVs is constrained to a specific value 2.For every indicator variable, there is at least one other indicator variable (same or different LV) to whom the error variances DO NOT covary.
29.2.2.1.4 Empirical Underidentification
You get underidentificaiton if one of the parameters is not equal to 0. If the error is greater than 0 you have too much information with too little of parameters. Now if one of the errors equals 0, then what happens is that the model then requires estimating two separate LVs.
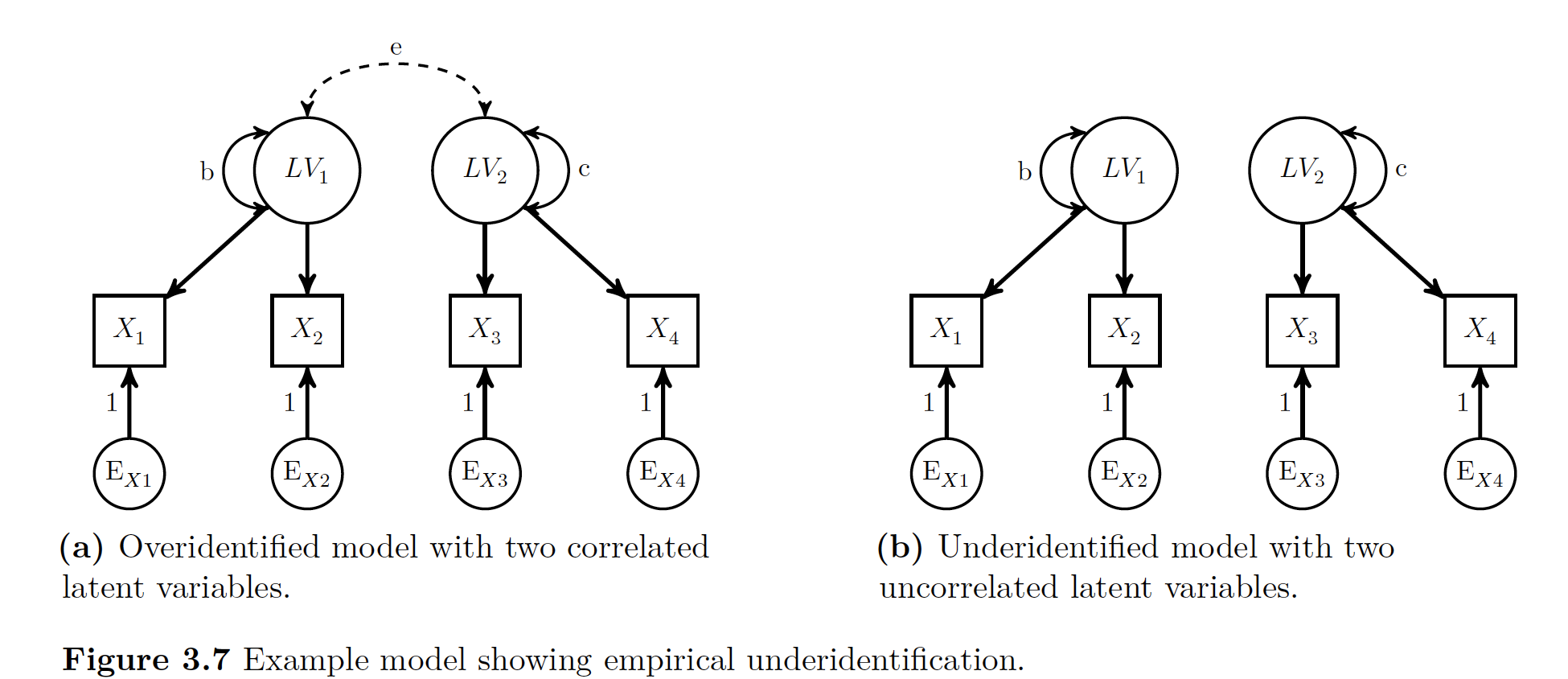
ASDF
==Doing it With One Latent Variable in R==
Data:
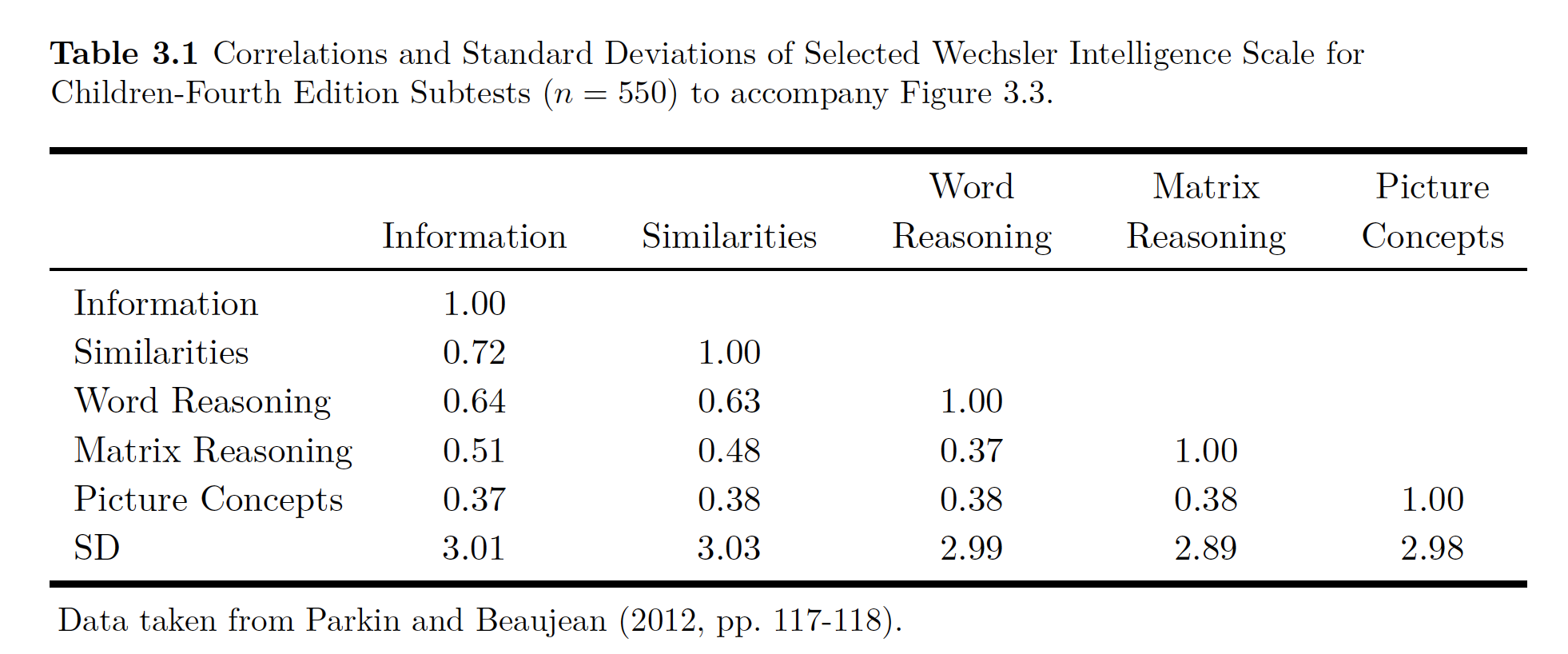
Data
library(lavaan)
#convert vector of correlations into matrix
wisc4.cor <- lav_matrix_lower2full(c(1,.72,1,.64,.63,1,.51,.48,.37,1,.37,.38,.38,.38,1))
colnames(wisc4.cor) <- rownames(wisc4.cor) <- c(
"Information",
"Similarities",
"Word.Reasoning",
"Matrix.Reasoning",
"Picture.Concepts")
#Enter SDs
wisc4.sd <- c(3.01, 3.03,2.99,2.89,2.98)
names(wisc4.sd) <- c(
"Information",
"Similarities",
"Word.Reasoning",
"Matrix.Reasoning",
"Picture.Concepts")
## Make correlations CVs via info from SD
wisc4.cov <- cor2cov(wisc4.cor,wisc4.sd)
#Designate Model
wisc4.model <- '
g =~ a*Information + b*Similarities + c*Word.Reasoning + d*Matrix.Reasoning + e*Picture.Concepts
'
wisc4.fit <- cfa(model = wisc4.model,sample.cov = wisc4.cov,sample.nobs = 550, std.lv=FALSE)
# First two above are model and data
# Second says how big is your sample size
# Standard with lavaan is use first LV as indicator, which is redundant with std.lv=FALSE
# If you put it as TRUE it scales ''g'' by standardizing it, estimate all loadings w SD of LV = 1
summary(wisc4.fit, standardized=TRUE)## lavaan (0.5-23.1097) converged normally after 30 iterations
##
## Number of observations 550
##
## Estimator ML
## Minimum Function Test Statistic 26.775
## Degrees of freedom 5
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Information Expected
## Standard Errors Standard
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## g =~
## Informatin (a) 1.000 2.578 0.857
## Similarits (b) 0.985 0.045 21.708 0.000 2.541 0.839
## Word.Rsnng (c) 0.860 0.045 18.952 0.000 2.217 0.742
## Mtrx.Rsnng (d) 0.647 0.047 13.896 0.000 1.669 0.578
## Pctr.Cncpt (e) 0.542 0.050 10.937 0.000 1.398 0.470
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Information 2.395 0.250 9.587 0.000 2.395 0.265
## .Similarities 2.709 0.258 10.482 0.000 2.709 0.296
## .Word.Reasoning 4.009 0.295 13.600 0.000 4.009 0.449
## .Matrix.Reasnng 5.551 0.360 15.400 0.000 5.551 0.666
## .Picture.Cncpts 6.909 0.434 15.922 0.000 6.909 0.779
## g 6.648 0.564 11.788 0.000 1.000 1.000# If you put standardized=TRUE it gives BOTH standardized and unstandardized values
# Estimate column is the raw scores with marker variable to scale LV
# NOTE THERE ARE TWO TYPES OF STANDARDIZED SCORES
# 1. Std.lv Standardizes LV, but leaves MV in RAW
# 2. Std.all Standardizes both LV and MV!!
parameterEstimates(wisc4.fit, standardized = TRUE, ci =FALSE)## lhs op rhs label est se z pvalue
## 1 g =~ Information a 1.000 0.000 NA NA
## 2 g =~ Similarities b 0.985 0.045 21.708 0
## 3 g =~ Word.Reasoning c 0.860 0.045 18.952 0
## 4 g =~ Matrix.Reasoning d 0.647 0.047 13.896 0
## 5 g =~ Picture.Concepts e 0.542 0.050 10.937 0
## 6 Information ~~ Information 2.395 0.250 9.587 0
## 7 Similarities ~~ Similarities 2.709 0.258 10.482 0
## 8 Word.Reasoning ~~ Word.Reasoning 4.009 0.295 13.600 0
## 9 Matrix.Reasoning ~~ Matrix.Reasoning 5.551 0.360 15.400 0
## 10 Picture.Concepts ~~ Picture.Concepts 6.909 0.434 15.922 0
## 11 g ~~ g 6.648 0.564 11.788 0
## std.lv std.all std.nox
## 1 2.578 0.857 0.857
## 2 2.541 0.839 0.839
## 3 2.217 0.742 0.742
## 4 1.669 0.578 0.578
## 5 1.398 0.470 0.470
## 6 2.395 0.265 0.265
## 7 2.709 0.296 0.296
## 8 4.009 0.449 0.449
## 9 5.551 0.666 0.666
## 10 6.909 0.779 0.779
## 11 1.000 1.000 1.000Note above that we define the LV of g using all five subsets of the WISC subtests.
Now we estimate the parameters with the cfa() function, as seen above.
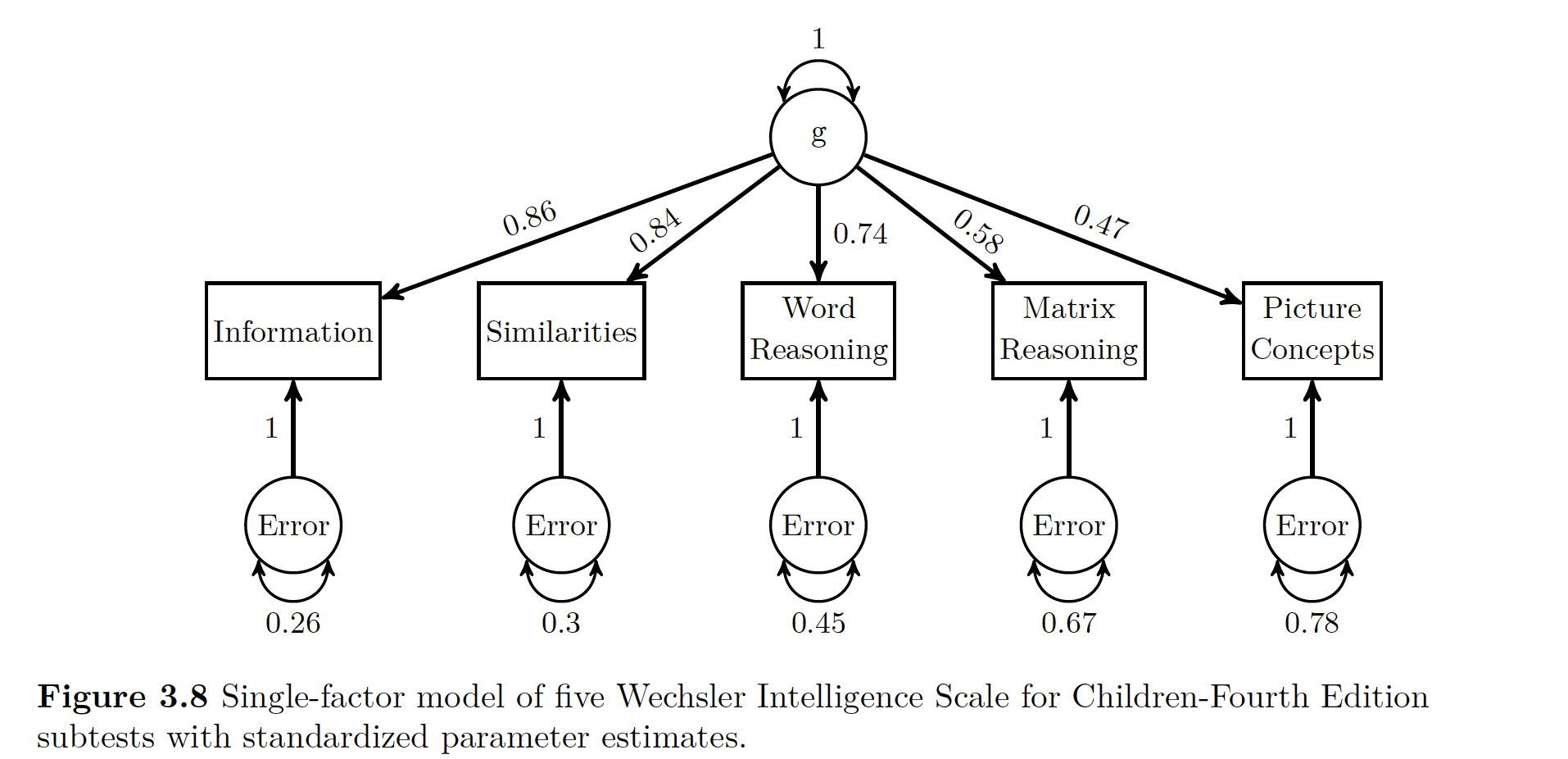
Data
Note the top part of the summary output lets you know if you put your model in correctly.
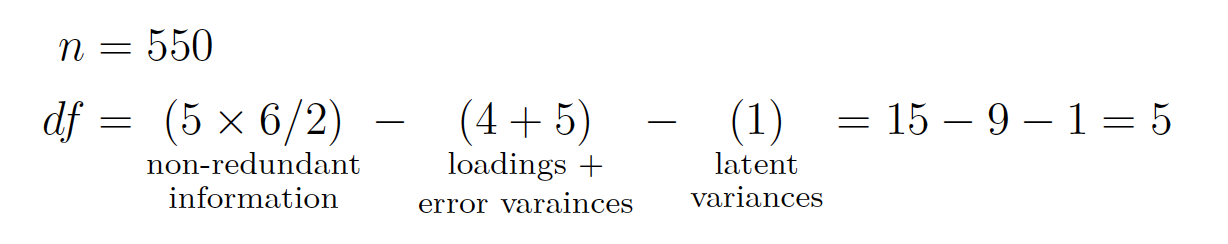
Data
Note that lavaan does not produce communality estimates. Though you can calculate them using the trace rules. You could figure out communality for the Information variable
\[ a x 1 x a = a^2 = 0.86^2 = 0.74\]
Thus uniqueness is
\[ 1- a^2 = 1 - 0.86^2 = 0.26\]
In addition to communality, you can use tracing rules and standardized parameter estimates to calculated the correlations implied by the model’s parameter estimates which you can then compare to the actual correlations you used in the original model. For example you could look at the relationship between Information and Similarities. If you go way up to Figure 3.3 you can see the only way you can get from one to the other is going through ’‘a’ to ’‘b’‘, so you multiply your’‘ab’’ loadings \((0.86)(0.84) = 0.72\). This number almost exactly matches our correlation from the raw data!
You can then use the fitted() function in lavaan to to get all the model implied-covariances.
Taken from the book…
## $cov
## Infrmt Smlrts Wrd.Rs Mtrx.R Pctr.C
## Information 9.044
## Similarities 6.551 9.164
## Word.Reasoning 5.716 5.633 8.924
## Matrix.Reasoning 4.303 4.241 3.700 8.337
## Picture.Concepts 3.606 3.553 3.100 2.334 8.864
##
## $mean
## Information Similarities Word.Reasoning Matrix.Reasoning
## 0 0 0 0
## Picture.Concepts
## 0#Transform Model Implied Covarianes to correlations
wisc4Fit.cov <- fitted(wisc4.fit)$cov
wisc4Fit.cor <- cov2cor(wisc4.cov)
#Original Correlations
wisc4.cor## Information Similarities Word.Reasoning Matrix.Reasoning
## Information 1.00 0.72 0.64 0.51
## Similarities 0.72 1.00 0.63 0.48
## Word.Reasoning 0.64 0.63 1.00 0.37
## Matrix.Reasoning 0.51 0.48 0.37 1.00
## Picture.Concepts 0.37 0.38 0.38 0.38
## Picture.Concepts
## Information 0.37
## Similarities 0.38
## Word.Reasoning 0.38
## Matrix.Reasoning 0.38
## Picture.Concepts 1.00## $type
## [1] "cor.bollen"
##
## $cor
## Infrmt Smlrts Wrd.Rs Mtrx.R Pctr.C
## Information 0.000
## Similarities 0.000 0.000
## Word.Reasoning 0.004 0.007 0.000
## Matrix.Reasoning 0.014 -0.005 -0.059 0.000
## Picture.Concepts -0.033 -0.014 0.031 0.109 0.000
##
## $mean
## Information Similarities Word.Reasoning Matrix.Reasoning
## 0 0 0 0
## Picture.Concepts
## 0## npar fmin chisq
## 10.000 0.024 26.775
## df pvalue baseline.chisq
## 5.000 0.000 1073.427
## baseline.df baseline.pvalue cfi
## 10.000 0.000 0.980
## tli nnfi rfi
## 0.959 0.959 0.950
## nfi pnfi ifi
## 0.975 0.488 0.980
## rni logl unrestricted.logl
## 0.980 -6378.678 -6365.291
## aic bic ntotal
## 12777.357 12820.456 550.000
## bic2 rmsea rmsea.ci.lower
## 12788.712 0.089 0.058
## rmsea.ci.upper rmsea.pvalue rmr
## 0.123 0.022 0.298
## rmr_nomean srmr srmr_bentler
## 0.298 0.034 0.034
## srmr_bentler_nomean srmr_bollen srmr_bollen_nomean
## 0.034 0.034 0.034
## srmr_mplus srmr_mplus_nomean cn_05
## 0.034 0.034 228.408
## cn_01 gfi agfi
## 310.899 0.982 0.947
## pgfi mfi ecvi
## 0.327 0.980 0.085## lhs op rhs mi epc sepc.lv sepc.all
## 12 Information ~~ Similarities 0.010 0.034 0.034 0.004
## 13 Information ~~ Word.Reasoning 0.279 0.147 0.147 0.016
## 14 Information ~~ Matrix.Reasoning 1.447 0.280 0.280 0.032
## 15 Information ~~ Picture.Concepts 5.493 -0.565 -0.565 -0.063
## 16 Similarities ~~ Word.Reasoning 0.791 0.242 0.242 0.027
## 17 Similarities ~~ Matrix.Reasoning 0.147 -0.089 -0.089 -0.010
## 18 Similarities ~~ Picture.Concepts 0.838 -0.223 -0.223 -0.025
## 19 Word.Reasoning ~~ Matrix.Reasoning 8.931 -0.710 -0.710 -0.082
## 20 Word.Reasoning ~~ Picture.Concepts 2.029 0.365 0.365 0.041
## 21 Matrix.Reasoning ~~ Picture.Concepts 14.157 1.058 1.058 0.123
## sepc.nox
## 12 0.004
## 13 0.016
## 14 0.032
## 15 -0.063
## 16 0.027
## 17 -0.010
## 18 -0.025
## 19 -0.082
## 20 0.041
## 21 0.12329.2.2.2 Alternative Latent Variable Scaling
So before we fit our model with lavaan’s default marker variable method. We can also do it with the standardized LV and the effects-coding method of LV scaling.
See the code below on how to do this!
# Marker Variable
wisc4.model.Std <- '
g =~ NA*Information + a*Information + b*Similarities + c*Word.Reasoning + d*Matrix.Reasoning + e*Picture.Concepts
# constrain LV Variance to 1
g~~1*g
'
wisc4.fit.Std <- cfa(wisc4.model.Std, sample.cov = wisc4.cov, sample.nobs = 550)
# AND
wisc4.model.effects <- '
g =~ NA*Information + a*Information + b*Similarities + c*Word.Reasoning + d*Matrix.Reasoning + e*Picture.Concepts
#Constrain Loadings Sums To One
a + b + c + d + e == 5
'
wisc4.fit.effects <- cfa(wisc4.model.effects,sample.cov = wisc4.cov, sample.nobs = 550)29.2.3 Doing it With Two Latent Variables in R
Let’s say we wanted to split our theorized g into two different LVs representing Verbal Comprehension and Fluid Reasoning.
wisc4.model2 <- '
V =~ a*Information + b*Similarities + c*Word.Reasoning
F =~ d*Matrix.Reasoning + e*Picture.Concepts
V~~f*F
'
wisc4.fit2 <- cfa(wisc4.model2,sample.cov = wisc4.cov, sample.nobs = 550)Data R Code is Modeling :
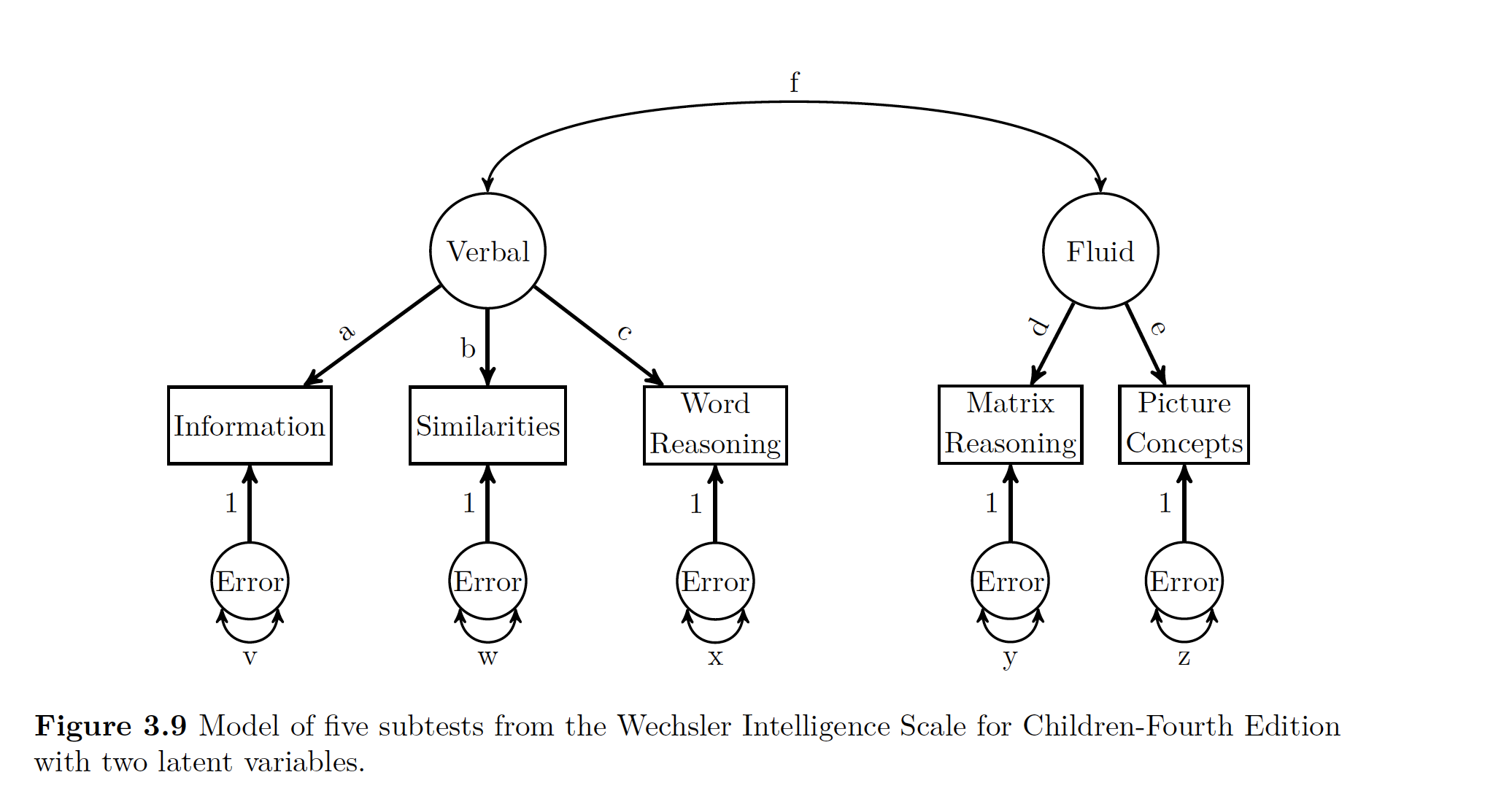
Data
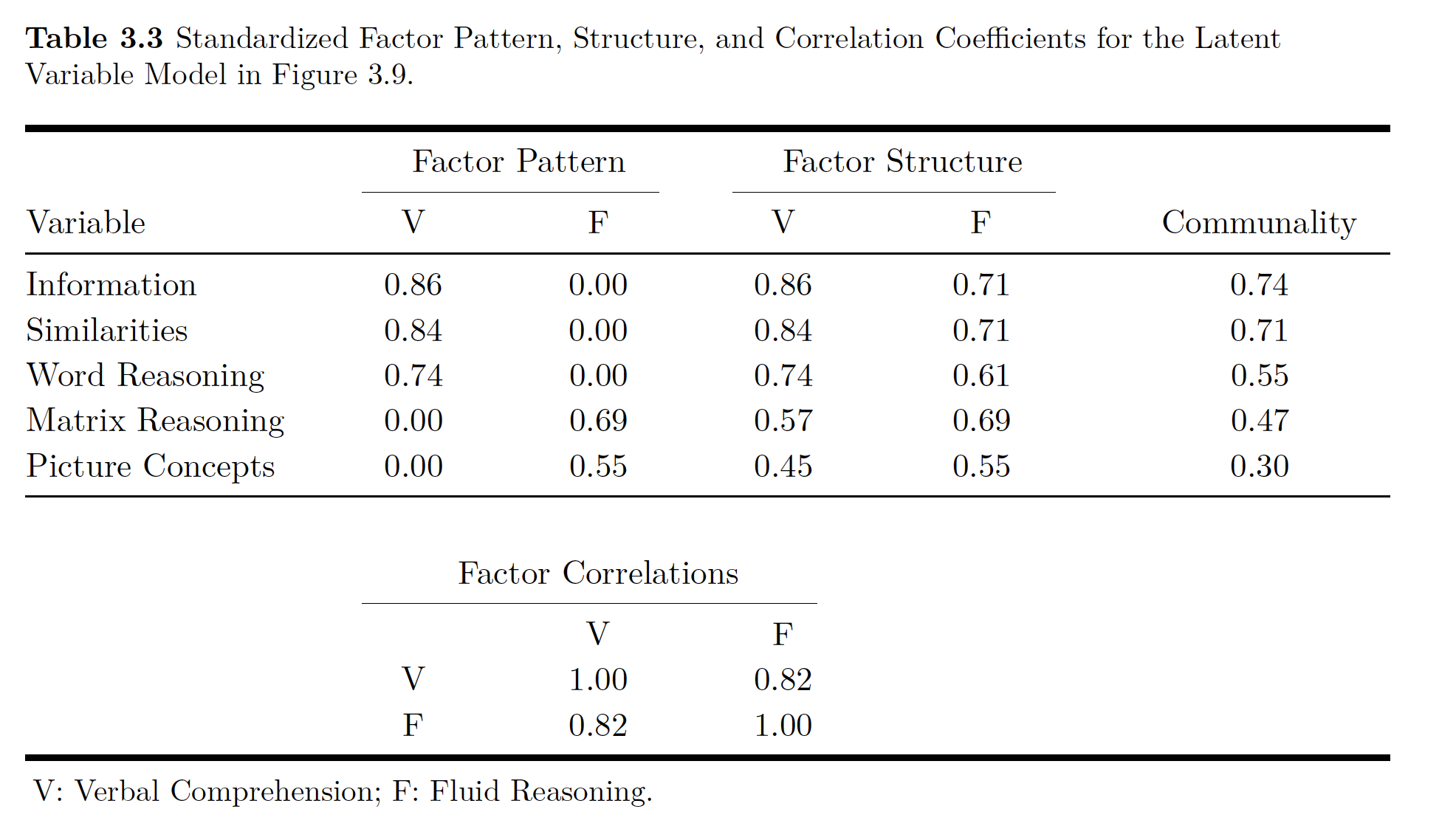
Data
29.2.4 Doing SEM in R
SEM = LVM + Path Analysis. Here we think Fluid Reasoning has a direct influence on Verbal Comprehension LV.
To use sem() in R, we need to use both LV operators (=~) and regression operators ( ~).
##SEM
wisc4.SEM.model <- '
#Define Latent Variables, just like above!
V =~ a*Information + b*Similarities + c*Word.Reasoning
F =~ d*Matrix.Reasoning + e*Picture.Concepts
# Define Structural Relations
V~k*F
'
wisc4.SEM.fit <- sem(wisc4.SEM.model, sample.cov = wisc4.cov, sample.nobs = 550)
summary(wisc4.SEM.fit, standardized=TRUE)## lavaan (0.5-23.1097) converged normally after 39 iterations
##
## Number of observations 550
##
## Estimator ML
## Minimum Function Test Statistic 12.687
## Degrees of freedom 4
## P-value (Chi-square) 0.013
##
## Parameter Estimates:
##
## Information Expected
## Standard Errors Standard
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## V =~
## Informatin (a) 1.000 2.587 0.860
## Similarits (b) 0.984 0.046 21.625 0.000 2.545 0.841
## Word.Rsnng (c) 0.858 0.045 18.958 0.000 2.219 0.743
## F =~
## Mtrx.Rsnng (d) 1.000 1.989 0.689
## Pctr.Cncpt (e) 0.825 0.085 9.747 0.000 1.642 0.552
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## V ~
## F (k) 1.070 0.114 9.376 0.000 0.823 0.823
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Information 2.352 0.253 9.295 0.000 2.352 0.260
## .Similarities 2.685 0.261 10.282 0.000 2.685 0.293
## .Word.Reasoning 4.000 0.295 13.555 0.000 4.000 0.448
## .Matrix.Reasnng 4.380 0.458 9.557 0.000 4.380 0.525
## .Picture.Cncpts 6.168 0.451 13.673 0.000 6.168 0.696
## .V 2.164 0.485 4.464 0.000 0.323 0.323
## F 3.957 0.569 6.960 0.000 1.000 1.000Note that in the output we have both a latent and a regression section. If you look at the picture below of what we are modeling, note that Verbal Comprehension in Endogenous (aka not measureable directly!), it’s reported variance is the error variance! AKA the variance not explained by Fluid Reasoning.
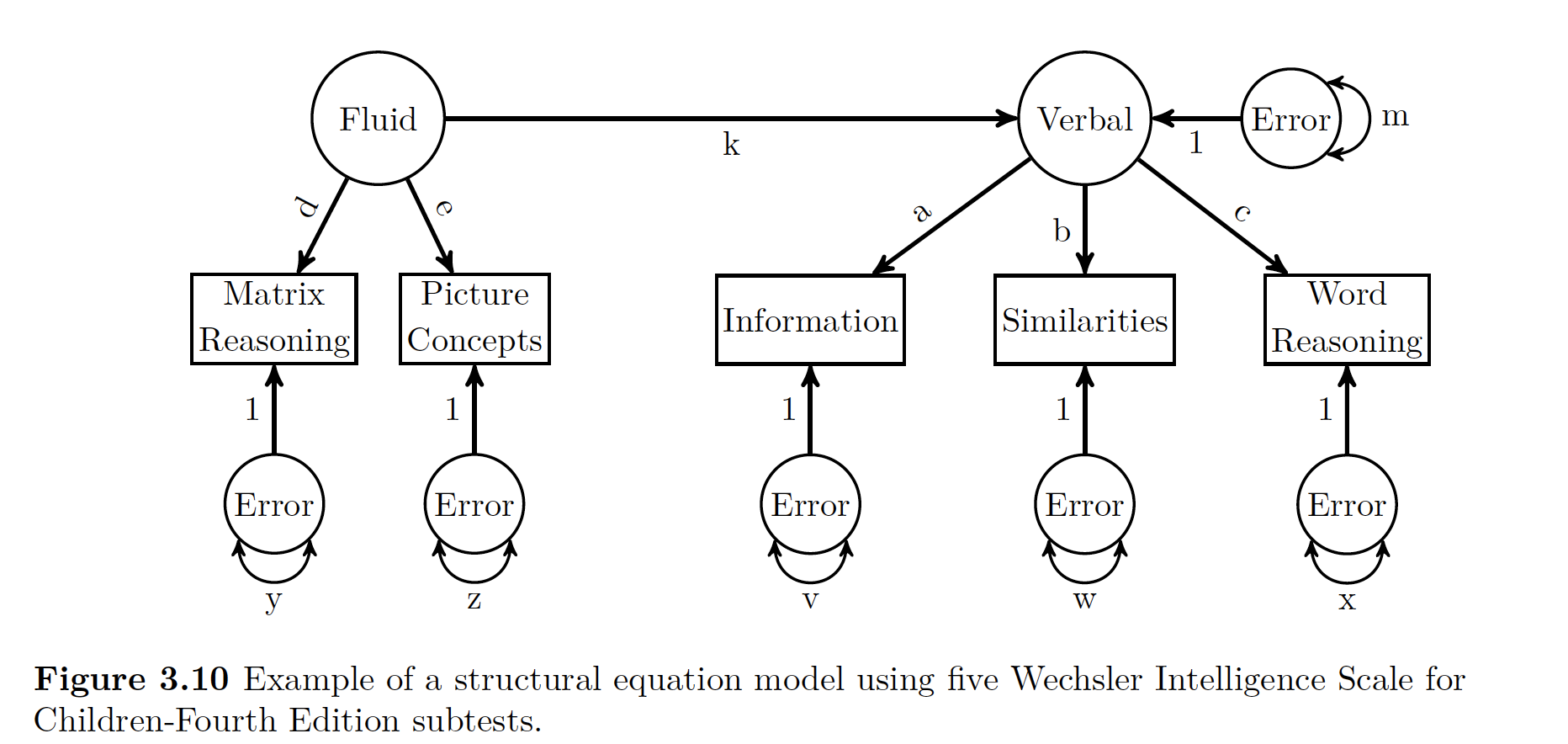
Data
29.2.5 Reporting Results
Should include
- A theoretical and empirical justification for the hypothesized model
- Complete descriptions of how LVMs were specified
- Description of Sample
- Type of Data used with descriptive stats
- Tests of Assumptions
- How Missing data was handled
- Software used
- Measured and criteria used to fit model
- Alteration made to the model
Tables should have * Parameter estimates * Standard Errors * Standardized versions of the final model * Other significant models that were fit * Path Model