Chapter 6 Experiment
6.1 Rationale
Using experiments to understand factors that contribute to an individual’s ability to remember melodic material are by no means new (Ortmann 1933). This is not a simple problem as noted in the Context, Literature, and Rationale, as both individual differences as well as musical features are difficult to quantify and subsequently model. Capturing variability at both the individual and item level is not only riddled with measurement problems, but this variability problem is exacerbated when realizing many of the statistical ramifications of measuring so many variables in a single experiment. Many variables leads to many tests, which leads to inflated type I error rates, as well as massive resources needed in order to detect even small effects.
Fortunately, dealing with high levels of variability at both the individual and item level is not a problem exclusive to work on melodic dictation. Work from from the field of linguistics has developed more sophisticated methodologies that are able to accommodate the above challenges and provide a more elegant way of handling these types of problems (Baayen, Davidson, and Bates 2008). In this chapter, I synthesize work from the previous chapters of this dissertation in an experiment investigating melodic dictation. Unlike work in the past literature, I take advantage of statistical methodologies that are able to better accommodate problems in experimental design using paradigms that accommodate for both individual and item level differences. By using mixed effects modeling, I put forward a more principled way of modeling data that more ecologically reflects melodic dictation. I show how it is possible to combine both tests of individual ability and as well as musical features in order to predict performance. Additionally, I discuss the intricacies associated with scoring and relate these practices back to the classroom.
6.2 Introduction
Despite its near ubiquity in Conservatory and School of Music curricula, research surrounding topics concerning aural skills is not well understood. This is peculiar since almost any individual seeking to earn a degree in music usually must enroll in multiple aural skills classes that cover a wide array of topics from sight-singing melodies, to melodic and harmonic dictation– all of which are presumed to be fundamental to any musician’s formal training. Skills acquired in these classes are meant to hone the musician’s ear and enable them not only to think about music, but to borrow Karpinski’s phrase, to “think in music” (Karpinski 2000, p.4;@bestMusicCurriculaFuture1992). The tacit assumption behind these tasks is that once one learns to think in music, these abilities should transfer to other aspects of the musician’s playing in a deep and profound way. The skills that make up an individual’s aural skills encompass many abilities, and are thought to be reflective of some sort of core skill. This logic is evident in early attempts to model performance in aural skills classes where Harrison, Asmus, and Serpe (1994) created a latent variable model to predict an individual’s success in aural skills classes based on musical aptitude, musical experience, motivation, and academic ability. While their model was able to predict a large amount of variance (73%), modeling at this high, conceptual level does not provide any sort of specific insights into the mental processes that are required for completing aural skills related tasks. This trend can also be seen in more recent research that has explored the relationship between how well entrance exams at the university level are able to predict success later on in the degree program.
Wolf and Kopiez (2014) noted multiple confounds in their study attempting to asses ability level in university musicians such as inflated grading, which led to ceiling effects, as well as a broad lack of consistency in how schools are assessing the success of their students. But even if the results at the larger level were to be clearer, this again says nothing about the processes that contribute to tasks like melodic dictation. Rather than taking a bird’s eye view of the subject, this chapter will primarily focus on descriptive factors that might contribute to an individual’s ability dictate a melody.
Melodic dictation is one of the central activities in an aural skills class. The activity normally consists of the instructor of the class playing a monophonic melody a limited number of times and the students must use both their ear, as well as their understanding of Western Music theory and notation, in order to transcribe the melody without any sort of external reference. No definitive method is taught across universities, but many schools of thought exist on the topic and a wealth of resources and materials have been suggested that might help students better complete these tasks (Berkowitz 2011; Cleland and Dobrea-Grindahl 2010; Karpinski 2007; Ottman and Rogers 2014) The lack of consistency could be attributed to the fact that there are so many variables at play during this process. Prior to listening, the student needs to have an understanding of Western music notation at least to the level of understanding the melody being played. This understanding must to be readily accessible, since as new musical information is heard, it is the student’s responsibility, in that moment, to essentially follow the Karpinski model and encode the melody in short term memory or pattern-match to long term memory (Oura 1991) so that they can identify what they are hearing and transcribe it moments later into Western notation (Karpinski 2000, 1990). Regardless, performing some sort of aural skills task requires both long term memory and knowledge for comprehension, as well as the ability to actively manipulate differing degrees of complex musical information in real time while concurrently writing it down.
Given the complexity of this task, as well as the difficulty in quantifying attributes of melodies, it is not surprising that scant research exists for describing these tasks. Fortunately, a fair amount of research exists in related literature which can generate theories and hypotheses explaining how individuals dictate melodies. Beginning first with factors that are less malleable from person to person would be individual differences in cognitive ability. While dictating melodies is something that is learned, a growing body of literature suggests that other factors can explain unique amounts of variance in performance via differences in cognitive ability. For example, Meinz and Hambrick (2010) found that measures of working memory capacity (WMC) were able to explain variance in an individual’s ability to sight read above and beyond that of sight reading experience and musical training. Colley, Keller, and Halpern (2017) recently suggested an individual’s WMC could also help explain differences beyond musical training in tasks related to tapping along to expressive timing in music. These issues become more confounded when considering other recent work by Swaminathan, Schellenberg, and Khalil (2017) that suggests factors such as musical aptitude, when considered in the modeling process, can better explain individual differences in intelligence between musicians and nonmusicians implying that there are selection biases at play within the musical population. They claim there is a selection bias that “smarter” people tend to gravitate towards studying music, which may explain some of the differences in memory thought to be caused by music study (Talamini et al. 2017). Knowing that these cognitive factors can play a role warrants attention from future researchers on controlling for variables that might contribute to this process, but are not directly intuitive and have not been considered in much of the past research. This is especially important given recent critique of models that purport to measure cognitive ability but are not grounded in an explanatory theoretical model (Kovacs and Conway 2016).
6.2.1 Memory for Melodies
The ability to understand how individuals encode melodies is at the heart of much of the music perception literature. Largely stemming from the work of Bregman (Bregman 2006), Deutsch and Feroe, (Deutsch and Feroe 1981), and Dowling’s (Bartlett and Dowling 1980; Dowling 1990, 1973, 1978) work on memory for melodies has sugested that both key and contour information play a central role in the perception and memory of novel melodies. Memory for melodies tends to be much worse than memory for other stimuli, such as pictures or faces, noting that the average area under the ROC curve tends to be at about .7 in many of the studies they reviewed, with .5 meaning chance and 1 being a perfect performance (Halpern and Bartlett 2010). Halpern and Bartlett also note that much of the literature on memory for melodies primarily used same-different experimental paradigms to investigate individuals’ melodic perception ability similar to the paradigm used in (Halpern and Müllensiefen 2008).
6.2.2 Musical Factors
Not nearly as much is known about how an individual learns melodies, especially in dictation settings. The last, and possibly most obvious, variable that would contribute to an individual’s ability to learn and dictate a melody would be the amount of previous exposure to the melody and the complexity of the melody itself. A fair amount of research from the music education literature examines melodic dictation in a more ecological setting (N. Buonviri 2015; Nathan O. Buonviri 2015; Buonviri 2017, 2014; Nathan O Buonviri and Paney 2015; Unsworth et al. 2005), but most take a descriptive approach to modeling the results using between-subject manipulations. Some rules of thumb regarding how many times a melody should be played in a dictation setting have been proposed by Karpinski (Karpinski 2000, 99) that account for chunking as well as the idea that more exposure would lead to more complete encoding. For example, he suggests using the formula \(P = (Ch/L) + 1\) where \(P\) is the number of playings, \(Ch\) is the number of chunks in the dictation (with chunk defined as a single memorable unit), and \(L\) = the limit of a listener’s short term memory in terms of chunks, a number between 6 and 10. This definition requires expert selection of what a chunk is, and does not take into account any of the Experimental factors put forward in the taxnomy presented in this dissertation’s Context, Literature, and Rationale.
Recently, tools have been developed in the field of computational musicology to help with operationalizing the complexity of melodies. Both simple and more complex features have been used to model performance in behavioral tasks. For example Eerola et al. (2006) found that note density, though not consciously apparent to the participants, predicted judgments of human similarity between melodies not familiar to the participants. Both Harrison, Musil, and Müllensiefen (2016) and Baker and Müllensiefen (2017) used measures of melodic complexity created from data reductive techniques to sucessfuly predict difficulty on melodic memory tasks.
Note density would be an ideal candidate to investigate because it is both easily measured and the amount of information that can be currently held in memory as measured by bits of information has a long history in cognitive psychology (Cowan 2005; George A. Miller 1956; Pearce 2018). In terms of more complex features, much of this work largely stems from the work of Müllensiefen and his development of the FANTASTIC Toolbox (2009), and a few papers have claimed to be able to predict various behavioral outcomes based on the structural characteristics of melodies. For example, (Kopiez and Mullensiefen 2011) claimed to have been able to predict how well songs from The Beatles’ album Revolver did on popularity charts based on structural characteristic of the melodies using a data driven approach. Expanding on an earlier study, (Müllensiefen and Halpern 2014) found that the degree of distinctiveness of a melody when compared to its parent corpus could be used to predict how participants in an old/new memory paradigm were able to recognize melodies. These abstracted features also have been used in various corpus studies (Jakubowski et al. 2017; Janssen, Burgoyne, and Honing 2017; Rainsford, Palmer, and Sauer 2019; Rainsford, Palmer, and Paine 2018) that again use data driven approaches in order to explain which of the 38 features that FANTASTIC calculates can predict real-world behavior.
While helpful and somewhat explanatory, the problem with either data reductive or data driven approaches to this modeling is that they take a post-hoc approach with the assumption that listeners are even able to abstract and perceive these features. Doing this does not allow for any sort of controlled approach. Without experimentally manipulating the parameters, which is then further confounded when using some sort of data reduction technique. This is understandable seeing as it is very difficult to manipulate certain qualities of a melody without disturbing other features (Taylor and Pembrook 1983). For example, if you wanted to decrease the “tonalness” of a melody by adding in a few more chromatic pitches, you inevitably will increase other measures of pitch and interval entropy. In order to truly understand if these features are driving changes in behaviour, each needs to be altered in some sort of controlled and systematic way while simultaneously considering differences in training and cognitive ability.
In order to accomplish this, I put forward findings from an experiment modeling performance on melodic dictation tasks using both individual and musical features. A pilot study was run (N=11) in order to assess musical confounds that might be present in modeling melodic dictation. Results of that pilot study are not reported here. Based on the results of this pilot data, a follow up experiment was conducted to better investigate the features in question.
The study sought to answer three main hypotheses:
- Are all experimental melodies used equally difficult to dictate?
- To what extent do the musical features of Note Density and Tonalness play a role in difficulty of dictation?
- Do individual factors at the cognitive level play a role in the melodic dictation process above and beyond musical factors?
6.3 Methods
6.3.1 Participants
Forty-three students enrolled at Louisiana State University School of Music completed the study. The inclusion criteria in the analysis included reporting no hearing loss, not actively taking medication that would alter cognitive performance, and individuals whose performance on any task performed greater than three standard deviations from the mean score of that task. Using these criteria, two participants were dropped for not completing the entire experiment. Thus, 41 participants met the criteria for inclusion. The eligible participants were between the ages of 17 and 26 (M = 19.81, SD = 1.93; 15 women). Participants volunteered, received course credit, or were paid $10.
6.3.2 Materials
Four melodies for the dictation were selected from a corpus of N=115 melodies derived from the A New Approach to Sight Singing aural skills textbook (Berkowitz 2011). Melodies were chosen based on their musical features as extracted via the FANTASTIC Toolbox (Mullensiefen 2009). After abstracting the full set of features of the melodies, possible melodies were first narrowed down by limiting the corpus to melodies lasting between 9 and 12 seconds and then indexed to select four melodies that were chosen as part of a 2 x 2 repeated measures design including a high and low tonalness and note density condition. Melodies, as well as a table of their abstracted features can be seen in ?? and 6.1, 6.2,??, and 6.4 . Melodies and other sounds used were encoded using MuseScore 2 using the standard piano timbre and all set to a tempo of quarter = 120 beats per minute and adjusted accordingly based on time signature to ensure they all were same absolute time duration. The experiment was then coded in jsPsych (de Leeuw 2015) and played through a browser offline with high quality headphones.
| Melodies | Tonalness | Note.Density | Design |
|---|---|---|---|
| 34 | 0.95 | 1.67 | High Tonal, Low Note Density |
| 112 | 0.98 | 3.73 | High Tonal, High Note Density |
| 9 | 0.71 | 1.75 | Low Tonal, Low Note Density |
| 95 | 0.76 | 3.91 | Low Tonal, High Note Density |

Figure 6.1: Melody 34

Figure 6.2: Melody 95

Figure 6.3: Melody 112

Figure 6.4: Melody 9
6.3.3 Procedure
Upon arrival, participants sat down in a lab at their own personal computer.
Multiple individuals were tested simultaneously although individually.
Each participant was given a test packet that contained all information needed for the experiment.
After obtaining written consent, participants navigated a series of instructions explaining the nature of the experiment and were given an opportunity to adjust the volume to a comfortable level.
The first portion of the experiment that participants completed was the melodic dictation.
In order to alleviate any anxiety in performance, participants were explicitly told that “unlike dictations performed in class, they were not expected to get perfect scores on their dictations”.
Each melody was played five times with 20 seconds between hearings and 120 seconds after the last hearing (Paney 2016).
After the dictation portion of the experiment, participants completed a small survey on their Aural Skills background, as well as the Bucknell Auditory Imagery Scale C (Halpern 2015).
After completing the Aural Skills portion of the experiment, participants completed one block of two different tests of working memory capacity (Unsworth et al. 2005) and Raven’s Advanced Progressive Matrices, and a Number Series task as two tests of general fluid intelligence (Gf) (Raven 1994; Thurstone 1938) resulting in four total scores.
Exact details of the design can be found in Chapter 3. After completing the cognitive battery, participants finished the experiment by compiling the self-report version of the Goldsmiths Musical Sophistication Index (Müllensiefen et al. 2014), the Short Test of Musical Preferences (Rentfrow and Gosling 2003), as well as questions pertaining to the participant’s socio-economic status, and any other information we needed to control for (Hearing Loss, Medication). Exact materials for the experiment can be found at https://github.com/davidjohnbaker1/modelingMelodicDictation).
6.3.4 Scoring Melodies
Melodies were scored by counting the amount of notes in the melody and multiplying that number by two. Half the points were attributed to rhythmic accuracy and the other half to pitch accuracy. Points were not deducted for notating the melody in the incorrect octave. Points for pitch could only be given if the participant correctly notated the rhythm. For example, in Melody 34 in Figure 6.1 there were 40 points possible (20 notes * 2). If a participant was to have put a quarter note on the second beat of the third measure, and have everything else correct, they would have scored a 19/20. Only if the correct rhythms of the measures were accurate could pitch points be awarded. In cases where there were more serious errors, for example if the second half of the second bar was not notated, points would have been deducted in both the pitch and rhythm sub-scores. Dictations were scored all melodies independently by two raters and then cross referenced for inter rater reliability (\(\kappa\) = .96) whic suggests a high degree of inter-rater reliability (Koo and Li 2016).
6.4 Results
6.4.1 Data Screening
Before conducting any analyses, data was screened for quality. List-wise deletion was used to remove any participants where not all variables were present. This process resulted in removing four participants: two did not complete any of the survey materials and two did not have any measures of working memory capacity due to computer error. After list-wise deletion, thirty-nine participants remained.
6.4.2 Modeling
In order to model the data and investigate the hypotheses, I fit a series of linear mixed effects models using the R programming langauge (R Core Team 2017) and the lme4 and LMERTEST (Bates et al. 2015) packages to predict scores from the dictation exercise using both individual and musical variables. Variables are added at each step and tests of significant model improvement are presented in Table ??. P-values were obtained by likelihood ratio tests between models. I also report AIC and BIC measures for each model ran. Models were ran sequentially moving from a null model to a theoretical, statistical model predicted by variables discussed above.
After establishing a null model (Model 1, null_model), I then added individual level predictors (wmc_model (Model 2) and gf_model, and cognitive_model) carrying forward only measures of working memory capacity.
No cognitive variables resulted in a significant increase in model fit.
Next, I modeled musical level features.
Each musical model that I ran allowed musical features to have random slopes since presumably individuals would perform differently on each melody.
The first muscial model (Model 3) treated each melody as a categorical fixed effect.
The second musical model (Model 4) used the categorical features as predictors, which included an interaction effect.
The third musical model (Model 5) used the continous FANTASTIC measures as fixed effects, which included an interaction effect.
In order to investigate claims put forward in the third chapter of this dissertation, I also ran a model (Model 6) using only interval entropy as calculated by FANTASTIC.
Finally, I ran two models that accounted for both musical and indiviual level predictors.
Model 7 exteneds Model 6, with the addition of working memory capacity as fixed effect, allowing for random slopes.
Model 8 extends Model 5, with the addition of working memory capacity as a fixed effect, allowing for random slopes.
I depict the fixed effects for all models in 6.5.
Tables for each model are presented in Tables ??, @(ref:metable2), @(ref:metable3), and ??.
| Df | AIC | BIC | logLik | deviance | Chisq | Chi Df | Pr(>Chisq) | |
|---|---|---|---|---|---|---|---|---|
| null_model | 3 | 62.73561 | 71.885181 | -28.36781 | 56.73561 | NA | NA | NA |
| wmc_model | 4 | 63.44881 | 75.648235 | -27.72441 | 55.44881 | 1.286802 | 1 | 0.2566381 |
| gf_model | 4 | 64.73129 | 76.930718 | -28.36565 | 56.73129 | 0.000000 | 0 | 1.0000000 |
| cognitive_model | 5 | 65.38048 | 80.629759 | -27.69024 | 55.38048 | 1.350815 | 1 | 0.2451357 |
| melody_model | 6 | -59.76827 | -41.469130 | 35.88413 | -71.76827 | 127.148745 | 1 | 0.0000000 |
| feature_category_model | 6 | -59.76827 | -41.469130 | 35.88413 | -71.76827 | 0.000000 | 0 | 1.0000000 |
| feature_ientropy_model | 6 | -28.80330 | -10.504165 | 20.40165 | -40.80330 | 0.000000 | 0 | 1.0000000 |
| total_model_ientropy | 7 | -22.83439 | -1.485395 | 18.41719 | -36.83439 | 0.000000 | 1 | 1.0000000 |
| feature_cont_model | 8 | -68.07246 | -43.673611 | 42.03623 | -84.07246 | 47.238072 | 1 | 0.0000000 |
| total_model_experimental | 9 | -56.97263 | -29.523924 | 37.48631 | -74.97263 | 0.000000 | 1 | 1.0000000 |
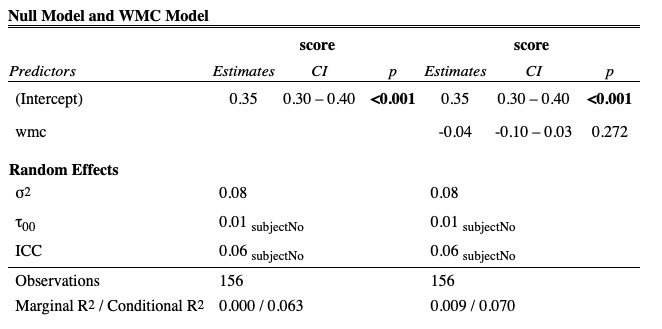
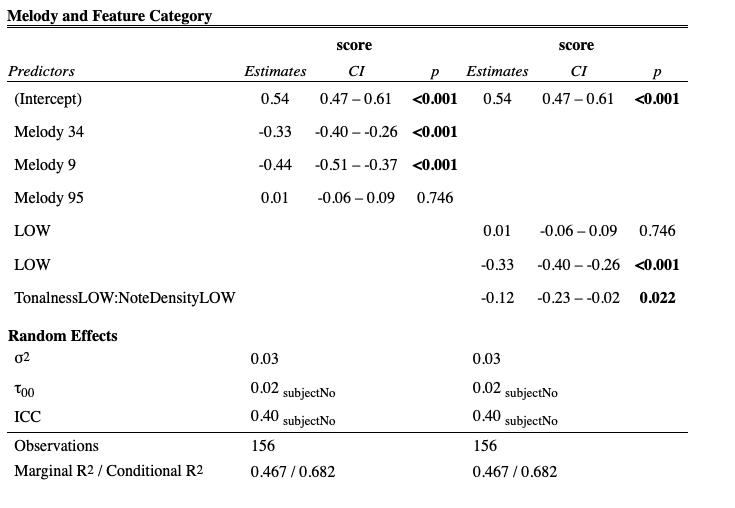
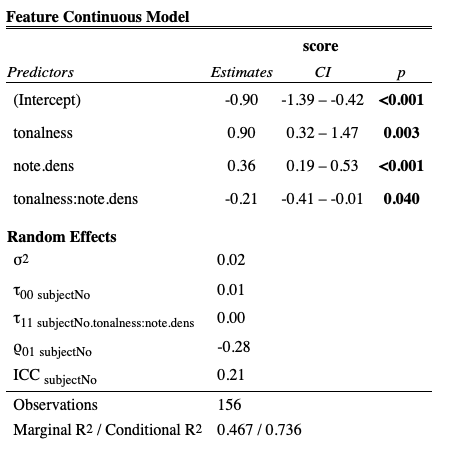
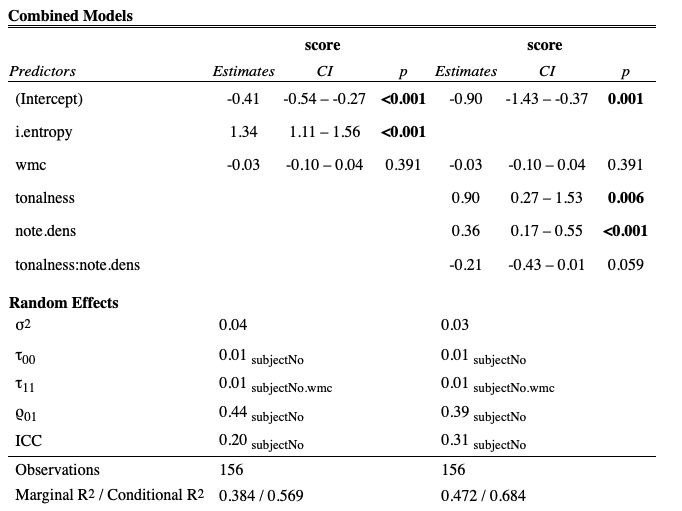
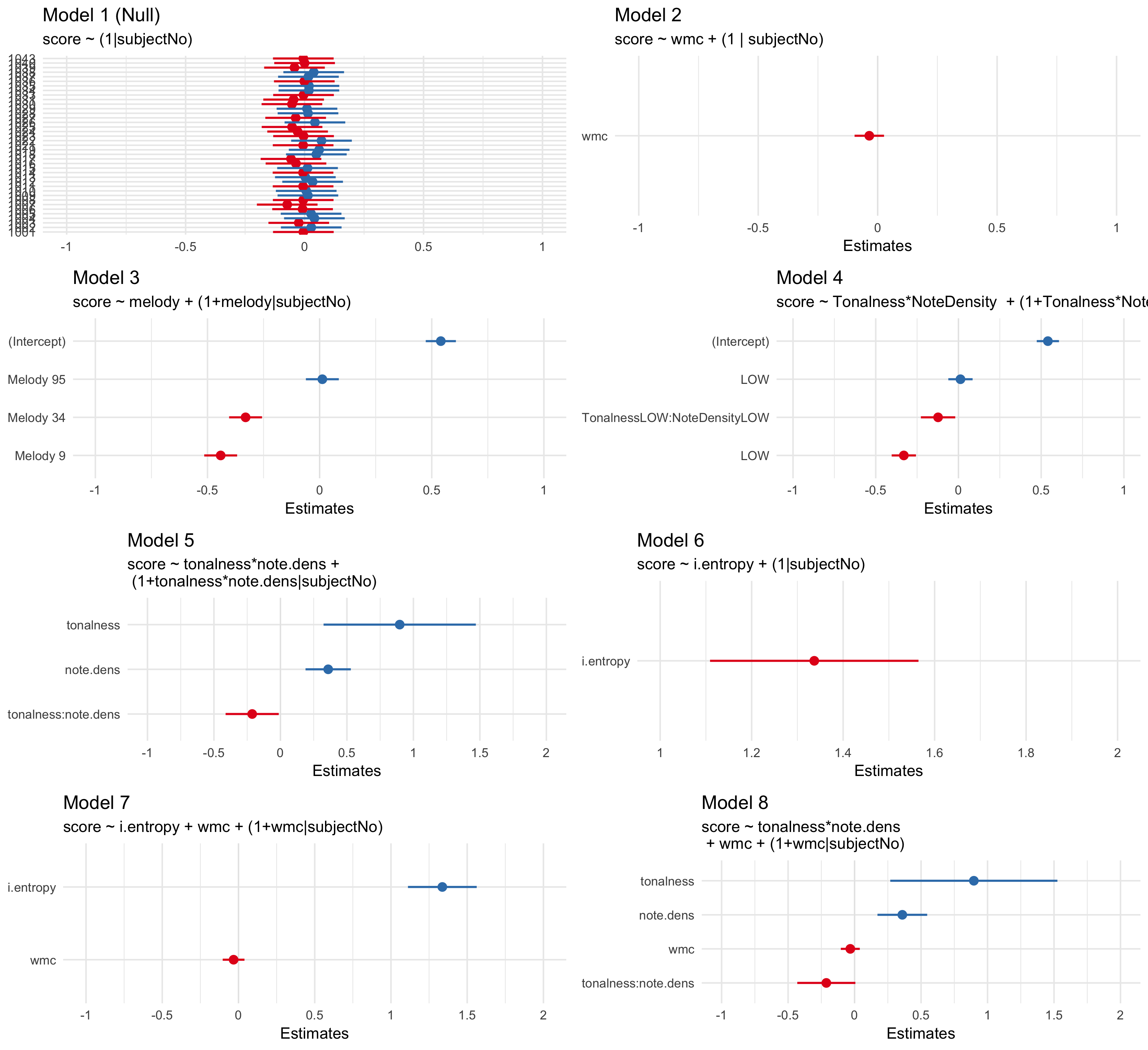
Figure 6.5: Fixed Effects of Models
Distributions for average scores of the melodies are found in 6.6 and density scores of these items are foudn in 6.7.
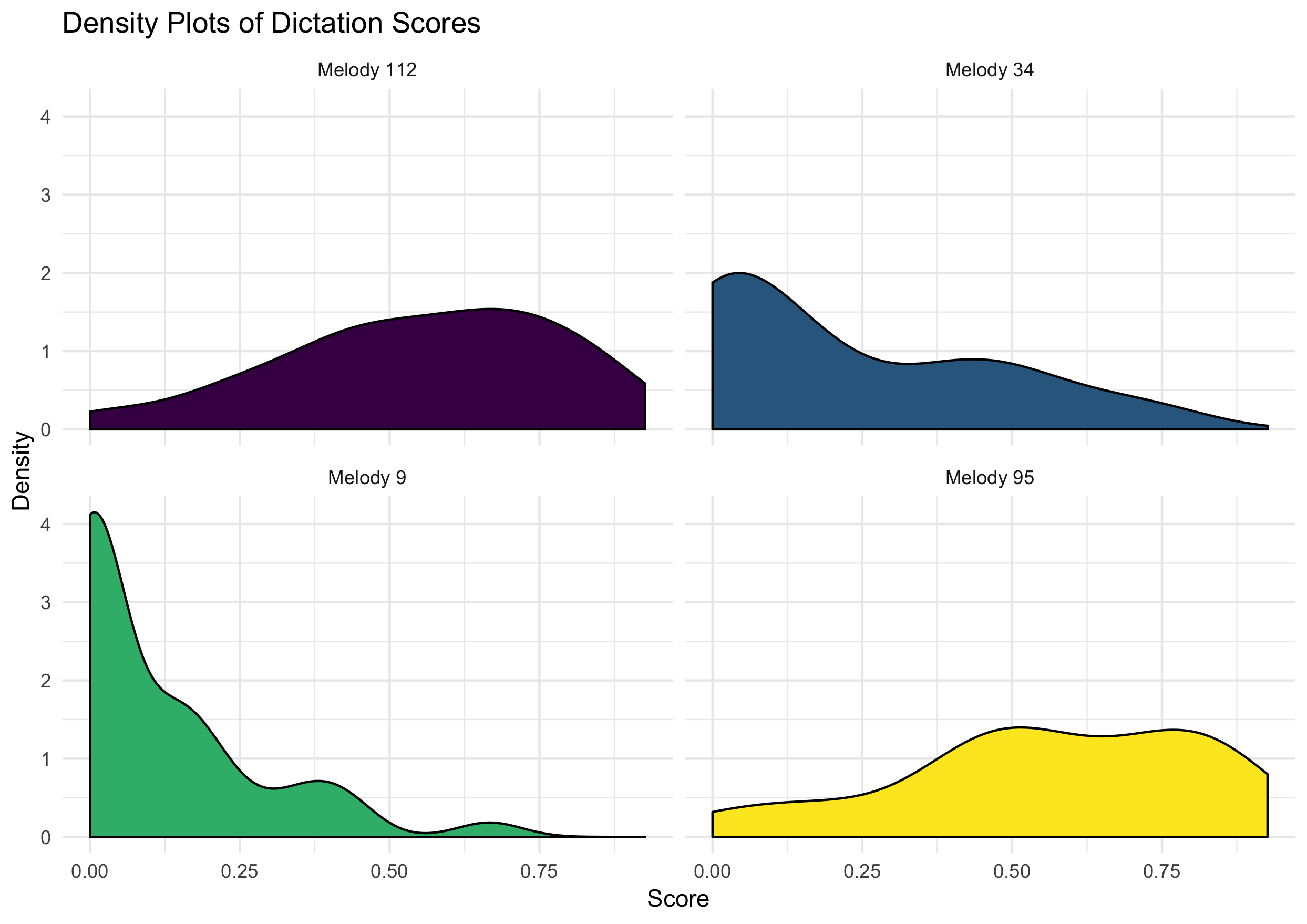
Figure 6.6: Melody Difficulty
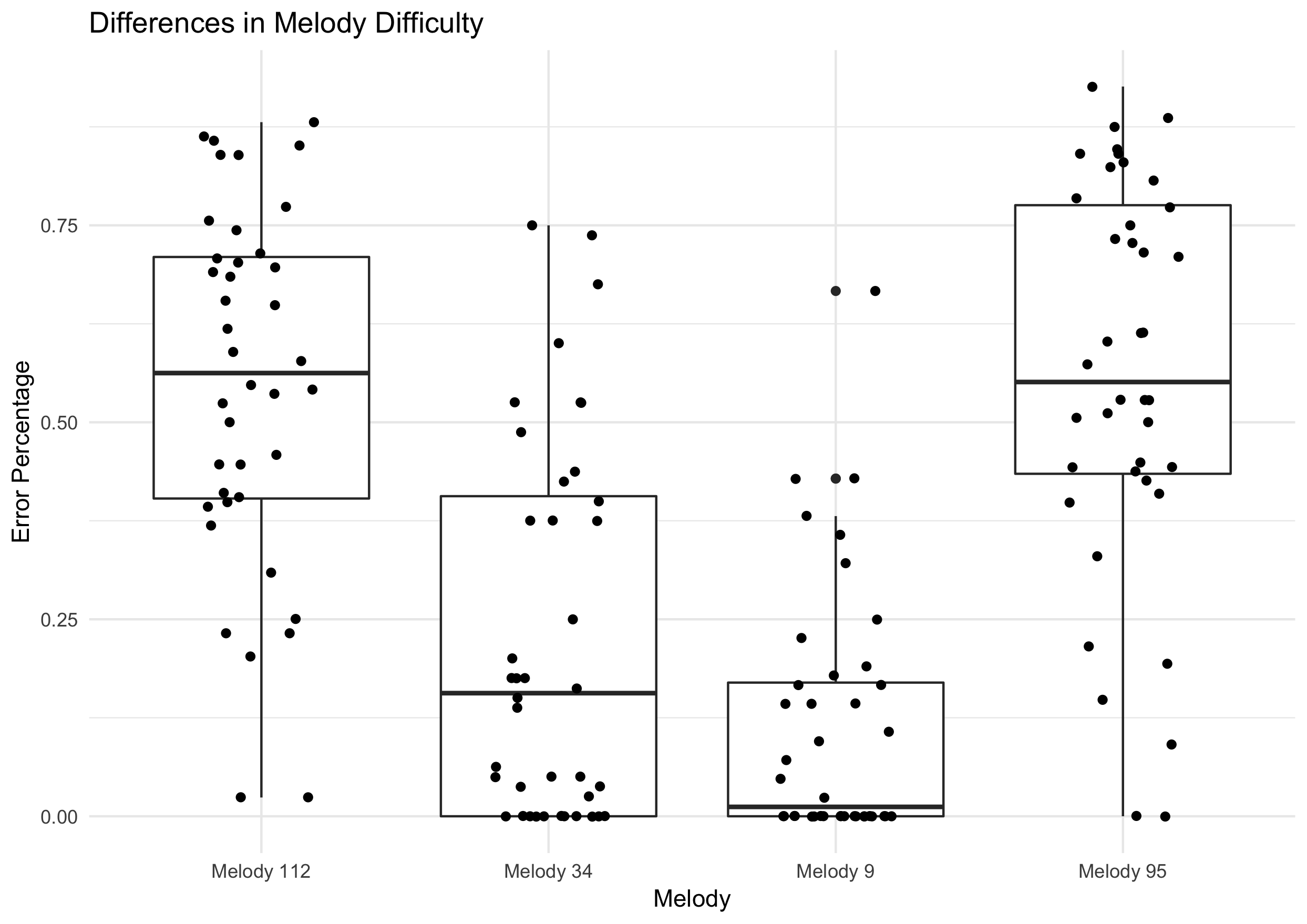
Figure 6.7: Melodic Differences
6.5 Discussion
In this chapter, I investigated the extent to which both individual differences and abstracted musical features could be used to model results in melodic dictations. In order to examine \(H1\), I ran a linear mixed effects model in order discern any differences in melody difficulty. As noted in ??, both a significant main effect of Tonalness and Note Density was found, as well as a small interaction between the two variables suggesting evidence supporting rejecting \(H2\)’s null hypothesis. The interaction emerged from differences in melody means in the low density conditions with the melody with higher tonalness actually scoring higher in terms of number of errors. Subsequent adding of individual level predictors did result in a better fitting model.
While I expected to find an interaction, this condition (Melody 34) was hypothesized to be the easiest of the four conditions. With Melody 9 there was a clear floor effect, which was also to be expected as when we chose the melodies, I had no previous experimental data explicitly looking at melodic dictation to rely on. Future experiments should use abstracted features from Melody 9 as a baseline in order to avoid floor effects.
The main effect of note density was expected and exhibited a large effect size. (\(\eta\) = .46). While it would be tempting to attribute this finding exactly to the Note Density feature extracted by FANTASTIC, the high and low density conditions could also be operationalized as having compound versus simple meter. Given the large effect of note density, I plan on taking more careful steps in the selection of our next melodies in order to control for any effects of meter and keep the effects limited to one meter if at all possible.
Somewhat surprisingly, the analysis incorporating the cognitive measures of covariance did not yield any significant results. While other researchers and the third Chapter of this disseratation have noted the importance of baseline cognitive ability (Schellenberg and W. Weiss 2013), the task specificity of doing melodic dictation as we designed the experiment might not be well suited to capture the variability needed for any effects. Hence, this chapter would not be able to reject H3’s null hypothesis. Considering that other researchers have found constructs like working memory capacity and general fluid intelligence to be important factors of tasks of musical perception, a more refined design might be considered in the future to find any sort of effects. Taken as a whole, these findings suggest that aural skills pedagogues should consider exploring the extent to which computationally extracted features can guide the difficulty expected of melodic dictation exercises.
6.6 Conclusions
This chapter demonstrated that abstracted musical features such as tonalness and note density can play a role in predicting how well students do in tasks of melodic dictation. While the experiment failed to yield any significant differences in cognitive ability predicting success at the task, future research plans should not fail to take these effects into consideration.
One important caveat in this modeling is that the models reported here are subject to change given other scoring procedures. There is a high degree of variability in how melodic dictations are scored (Gillespie 2001), and modeling how different scoring procedures lead to differing results should be considered for future research. Importantly, if a researcher adopted this paradigm for investigating melodic dictation, what is most important is that there is some sort of external reference a single scorer can compare themselves to. Without having a pre-defined metric, scoring and thus grading will be subjected to the scorer’s explicit or implicit biases. Given all that has been put forward here, the research thus far still does not explain the underlying processes for melodic dictation. In this chapter, I have put forward two factors that help describe what contributes to this process using a principled experimental framework. – sentence on principle.
References
Ortmann, Otto. 1933. “Some Tonal Determinants of Melodic Memory.” Journal of Educational Psychology 24 (6): 454–67. https://doi.org/10.1037/h0075218.
Baayen, R.H., D.J. Davidson, and D.M. Bates. 2008. “Mixed-Effects Modeling with Crossed Random Effects for Subjects and Items.” Journal of Memory and Language 59 (4): 390–412. https://doi.org/10.1016/j.jml.2007.12.005.
Karpinski, Gary Steven. 2000. Aural Skills Acquisition: The Development of Listening, Reading, and Performing Skills in College-Level Musicians. Oxford University Press.
Harrison, Carole S., Edward P. Asmus, and Richard T. Serpe. 1994. “Effects of Musical Aptitude, Academic Ability, Music Experience, and Motivation on Aural Skills.” Journal of Research in Music Education 42 (2): 131. https://doi.org/10.2307/3345497.
Wolf, Anna, and Reinhard Kopiez. 2014. “Do Grades Reflect the Development of Excellence in Music Students? The Prognostic Validity of Entrance Exams at Universities of Music.” Musicae Scientiae 18 (2): 232–48. https://doi.org/10.1177/1029864914530394.
Berkowitz, Sol, ed. 2011. A New Approach to Sight Singing. 5th ed. New York: W.W. Norton.
Cleland, Kent D., and Mary Dobrea-Grindahl. 2010. Developing Musicianship Through Aural Skills: A Holisitic Approach to Sight Singing and Ear Training. New York: Routledge.
Karpinski, Gary S. 2007. Manual for Ear Training and Sight Singing. New York: Norton.
Ottman, Robert W., and Nancy Rogers. 2014. Music for Sight Singing. 9th ed. Upper Saddle River, NJ: Pearson.
Oura, Yoko. 1991. “Constructing a Representation of a Melody: Transforming Melodic Segments into Reduced Pitch Patterns Operated on by Modifiers.” Music Perception: An Interdisciplinary Journal 9 (2): 251–65. https://doi.org/10.2307/40285531.
Karpinski, Gary. 1990. “A Model for Music Perception and Its Implications in Melodic Dictation.” Journal of Music Theory Pedagogy 4 (1): 191–229.
Meinz, Elizabeth J., and David Z. Hambrick. 2010. “Deliberate Practice Is Necessary but Not Sufficient to Explain Individual Differences in Piano Sight-Reading Skill: The Role of Working Memory Capacity.” Psychological Science 21 (7): 914–19. https://doi.org/10.1177/0956797610373933.
Colley, Ian D, Peter E Keller, and Andrea R Halpern. 2017. “Working Memory and Auditory Imagery Predict Sensorimotor Synchronisation with Expressively Timed Music.” Quarterly Journal of Experimental Psychology 71 (8): 1781–96. https://doi.org/10.1080/17470218.2017.1366531.
Swaminathan, Swathi, E. Glenn Schellenberg, and Safia Khalil. 2017. “Revisiting the Association Between Music Lessons and Intelligence: Training Effects or Music Aptitude?” Intelligence 62 (May): 119–24. https://doi.org/10.1016/j.intell.2017.03.005.
Talamini, Francesca, Gianmarco Altoè, Barbara Carretti, and Massimo Grassi. 2017. “Musicians Have Better Memory Than Nonmusicians: A Meta-Analysis.” Edited by Lutz Jäncke. PLOS ONE 12 (10): e0186773. https://doi.org/10.1371/journal.pone.0186773.
Kovacs, Kristof, and Andrew R. A. Conway. 2016. “Process Overlap Theory: A Unified Account of the General Factor of Intelligence.” Psychological Inquiry 27 (3): 151–77. https://doi.org/10.1080/1047840X.2016.1153946.
Bregman, Albert S. 2006. Auditory Scene Analysis: The Perceptual Organization of Sound. 2. paperback ed., repr. A Bradford Book. Cambridge, Mass.: MIT Press.
Deutsch, Diana, and John Feroe. 1981. “The Internal Representation of Pitch Sequences in Tonal Music.” Psychological Review 88 (6): 503–22.
Bartlett, James C, and W Jay Dowling. 1980. “Recognition of Transposed Melodies: A Key-Distance Effect in Developmental Perspective,” 15.
Dowling, W. 1990. “Expectancy and Attention in Melody Perception.” Psychomusicology: A Journal of Research in Music Cognition 9 (2): 148–60. https://doi.org/10.1037/h0094150.
Dowling, W.J. 1973. “The Perception of Interleaved Melodies.” Cognitive Psychology 5 (3): 322–37. https://doi.org/10.1016/0010-0285(73)90040-6.
Dowling, W. Jay. 1978. “Scale and Contour: Two Components of a Theory of Memory for Melodies.” Psychological Review 84 (4): 341–54.
Halpern, Andrea R., and James C. Bartlett. 2010. “Memory for Melodies.” In Music Perception, edited by Mari Riess Jones, Richard R. Fay, and Arthur N. Popper, 36:233–58. New York, NY: Springer New York. https://doi.org/10.1007/978-1-4419-6114-3_8.
Halpern, Andrea R., and Daniel Müllensiefen. 2008. “Effects of Timbre and Tempo Change on Memory for Music.” Quarterly Journal of Experimental Psychology 61 (9): 1371–84. https://doi.org/10.1080/17470210701508038.
Buonviri, Nathan. 2015. “Effects of Music Notation Reinforcement on Aural Memory for Melodies.” International Journal of Music Education 33 (4): 442–50. https://doi.org/10.1177/0255761415582345.
Buonviri, Nathan O. 2015. “Effects of a Preparatory Singing Pattern on Melodic Dictation Success.” Journal of Research in Music Education 63 (1): 102–13. https://doi.org/10.1177/0022429415570754.
Buonviri, Nathan O. 2017. “Effects of Two Listening Strategies for Melodic Dictation.” Journal of Research in Music Education 65 (3): 347–59. https://doi.org/10.1177/0022429417728925.
Buonviri, Nathan O. 2014. “An Exploration of Undergraduate Music Majors’ Melodic Dictation Strategies.” Update: Applications of Research in Music Education 33 (1): 21–30. https://doi.org/10.1177/8755123314521036.
Buonviri, Nathan O, and Andrew S Paney. 2015. “Melodic Dictation Instruction.” Journal of Research in Music Education 62 (2): 224–37.
Unsworth, Nash, Richard P. Heitz, Josef C. Schrock, and Randall W. Engle. 2005. “An Automated Version of the Operation Span Task.” Behavior Research Methods 37 (3): 498–505. https://doi.org/10.3758/BF03192720.
Eerola, Tuomas, Tommi Himberg, Petri Toiviainen, and Jukka Louhivuori. 2006. “Perceived Complexity of Western and African Folk Melodies by Western and African Listeners.” Psychology of Music 34 (3): 337–71. https://doi.org/10.1177/0305735606064842.
Harrison, Peter M.C., Jason Jiří Musil, and Daniel Müllensiefen. 2016. “Modelling Melodic Discrimination Tests: Descriptive and Explanatory Approaches.” Journal of New Music Research 45 (3): 265–80. https://doi.org/10.1080/09298215.2016.1197953.
Baker, David J., and Daniel Müllensiefen. 2017. “Perception of Leitmotives in Richard Wagner’s Der Ring Des Nibelungen.” Frontiers in Psychology 8 (May). https://doi.org/10.3389/fpsyg.2017.00662.
Cowan, Nelson. 2005. Working Memory Capacity. Working Memory Capacity. New York, NY, US: Psychology Press. https://doi.org/10.4324/9780203342398.
Miller, George A. 1956. “Information and Memory.” Scientific American 195 (2): 42–46. https://doi.org/10.1038/scientificamerican0856-42.
Pearce, Marcus T. 2018. “Statistical Learning and Probabilistic Prediction in Music Cognition: Mechanisms of Stylistic Enculturation: Enculturation: Statistical Learning and Prediction.” Annals of the New York Academy of Sciences 1423 (1): 378–95. https://doi.org/10.1111/nyas.13654.
Mullensiefen, Daniel. 2009. “Fantastic: Feature ANalysis Technology Accessing STatistics (in a Corpus): Technical Report V1.5.”
Kopiez, Reinhard, and Daniel Mullensiefen. 2011. “Auf Der Suche Nach Den ‘Popularitätsfaktoren’ in Den Song-Melodien Des Beatles-Albums Revolver: Eine Computergestützte Feature-Analyse [in Search of Features Explaining the Popularity of the Tunes from the Beatles Album Revolver: A Computer-Assisted Feature Analysis].” Musik Und Popularitat. Beitrage Zu Einer Kulturgeschichte Zwischen, 207–25.
Müllensiefen, Daniel, and Andrea R. Halpern. 2014. “The Role of Features and Context in Recognition of Novel Melodies.” Music Perception: An Interdisciplinary Journal 31 (5): 418–35. https://doi.org/10.1525/mp.2014.31.5.418.
Jakubowski, Kelly, Sebastian Finkel, Lauren Stewart, and Daniel Müllensiefen. 2017. “Dissecting an Earworm: Melodic Features and Song Popularity Predict Involuntary Musical Imagery.” Journal of Aesthetics, Creativity, and the Arts 11 (2): 112–35.
Janssen, Berit, John A. Burgoyne, and Henkjan Honing. 2017. “Predicting Variation of Folk Songs: A Corpus Analysis Study on the Memorability of Melodies.” Frontiers in Psychology 8 (April). https://doi.org/10.3389/fpsyg.2017.00621.
Rainsford, Miriam, Matthew A. Palmer, and James D. Sauer. 2019. “The Distinctiveness Effect in the Recognition of Whole Melodies.” Music Perception: An Interdisciplinary Journal 36 (3): 253–72. https://doi.org/10.1525/mp.2019.36.3.253.
Rainsford, M., M. A. Palmer, and G. Paine. 2018. “The MUSOS (MUsic SOftware System) Toolkit: A Computer-Based, Open Source Application for Testing Memory for Melodies.” Behavior Research Methods 50 (2): 684–702. https://doi.org/10.3758/s13428-017-0894-6.
Taylor, Jack A., and Randall G. Pembrook. 1983. “Strategies in Memory for Short Melodies: An Extension of Otto Ortmann’s 1933 Study.” Psychomusicology: A Journal of Research in Music Cognition 3 (1): 16–35. https://doi.org/10.1037/h0094258.
de Leeuw, Joshua R. 2015. “jsPsych: A JavaScript Library for Creating Behavioral Experiments in a Web Browser.” Behavior Research Methods 47 (1): 1–12. https://doi.org/10.3758/s13428-014-0458-y.
Paney, Andrew S. 2016. “The Effect of Directing Attention on Melodic Dictation Testing.” Psychology of Music 44 (1): 15–24. https://doi.org/10.1177/0305735614547409.
Halpern, Andrea R. 2015. “Differences in Auditory Imagery Self-Report Predict Neural and Behavioral Outcomes.” Psychomusicology: Music, Mind, and Brain 25 (1): 37–47. https://doi.org/10.1037/pmu0000081.
Raven, J. 1994. Manual for Raven’s Progressive Matrices and Mill Hill Vocabulary Scales.
Thurstone, L. L. 1938. Primary Mental Abilities. Chicago: University of Chicago Press.
Müllensiefen, Daniel, Bruno Gingras, Jason Musil, and Lauren Stewart. 2014. “The Musicality of Non-Musicians: An Index for Assessing Musical Sophistication in the General Population.” Edited by Joel Snyder. PLoS ONE 9 (2): e89642. https://doi.org/10.1371/journal.pone.0089642.
Rentfrow, Peter J., and Samuel D. Gosling. 2003. “The Do Re Mi’s of Everyday Life: The Structure and Personality Correlates of Music Preferences.” Journal of Personality and Social Psychology 84 (6): 1236–56. https://doi.org/10.1037/0022-3514.84.6.1236.
Koo, Terry K., and Mae Y. Li. 2016. “A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research.” Journal of Chiropractic Medicine 15 (2): 155–63. https://doi.org/10.1016/j.jcm.2016.02.012.
R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. “Fitting Linear Mixed-Effects Models Using Lme4.” Journal of Statistical Software 67 (1). https://doi.org/10.18637/jss.v067.i01.
Schellenberg, E. Glenn, and Michael W. Weiss. 2013. “Music and Cognitive Abilities.” In The Psychology of Music, 499–550. Elsevier. https://doi.org/10.1016/B978-0-12-381460-9.00012-2.
Gillespie, Jeffrey L. 2001. “Melodic Dictation Scoring Methods: An Exploratory Study.” Journal for Music Theory Pedagogy 15.