Chapter 7 Computational Model
7.1 Levels of Abstraction
In his 2007 article Models of Music Similarity, Geraint Wiggins distinguishes between descriptive and explanatory models in describing the modeling of human behavior (Wiggins 2007). Descriptive models assert what will happen in response to an event. For example, as discussed in the previous chapter, as the note density of a melody increases and the tonalness of a melody decreases, a melody becomes more difficult to dictate. While the increase in note density is assumed to drive the decrease in dictation scores, merely stating that there is an established relationship between one variable and the other says nothing about the inner workings of this process. An explanatory model on the other hand, not only describes what will happen, but additionally notes why and how this process occurs. For example, much of the work from musical expectation demonstrates that as an individual’s exposure to a musical style increases, so does their ability to predict specific events within a given musical texture (Pearce 2018).
Not only does more exposure predict more accurate responses, but many of these models of musical expectation derive their underlying predictive power from the brain’s ability to implicitly track statistical regularities in an auditory scene (Saffran et al. 1999; Margulis 2014). The how derives from the tracking of statistical regularities in musical information and the why derives from evolutionary demands; Organisms that are able to make more accurate predictions about their environment are more likely to survive and pass on their genes (Huron 2006).
Wiggins writes that although there can be both explanatory and descriptive theories, depending on the level of abstraction, a theory may be explanatory at one level, yet descriptive at another. Using the mind-brain dichotomy, he asserts that the example of a theory of musical expectation could be explanatory at the level of behavior as noted above, but says nothing about what is happening at the neural level. Both descriptive and explanatory theories are needed: descriptive theories are used to test explanatory theories. By stringing together different layers of abstraction, we can arrive at a better understanding of how the world works.
Returning to melodic dictation, under Wiggins’ framework the Karpinski model of melodic dictation (Karpinski 2000, 1990) qualifies as a descriptive model. The model explains what happens over the time course of a melodic dictation– specifying four discrete stages discussed in earlier chapters– but does not explicitly state how or why this process happens. In order to have a more complete understanding of melodic dictation, an explanatory model is needed.
In this chapter, I introduce an explanatory model of melodic dictation. The model is inspired by work from both computational musicology and cognitive psychology. From computational musicology, I draw on the work of Marcus Pearce’s IDyOM (Pearce 2005) and from cognitive psychology, I draw on Nelson Cowan’s Embedded Process model of working memory (Cowan 1988, 2010) to explain the perceptual components. In addition to quantifying each step, the model incorporates flexible parameters that can be adjusted in order to accommodate individual differences, while still relying on a domain general process. By relying on cognitive mechanisms based in statistical learning rather than a rule based system for music analysis (Lerdahl and Jackendoff 1986; Narmour 1990, 1992; Temperley 2004), this model allows for the heterogeneity of musical experience among a diversity of music listeners.
7.2 Model Overview
The model consists of three main modules, each with its own set of parameters:
- Prior Knowledge
- Selective Attention
- Transcription and Re-entry
The Prior Knowledge module reflects the previous knowledge an individual brings to the melodic dictation. The Selective Attention module– somewhat akin to Karpinski’s extractive listening (Karpinski 2000, 1990)– segments incoming musical information by using the window of attention as conceptualized as the limits of working memory capacity as a sensory bottleneck to constrict the size of musical chunk that an individual could transcribe. Once musical material is in the focus of attention, the Transcription function pattern matches against the Prior Knowledge’s corpus of information in order to find a match of explicitly known musical information. The Transcription function will recursively truncate what musical information is in Selective Attention if no match is found. In addition to Transcription, there is also a Re-entry function that will restart the entire loop. This process reflects, but is not intended to mirror the cognitive process used in melodic dictation. Rather it attempts to be phenomenologically similar to the decision making process used when attempting to notate novel melodies. Based on both the prior knowledge and individual differences of the individual, the model will scale in ability, with the general retrieval mechanisms in place. The exact details of the assumptions, parameters, and complete formula of the model are discussed below.
7.3 Verbal Model
Below I describe my model’s assumptions, parameters, as well as the steps taken when the model is run. After detailing the inner workings of each of the assumptions and the modules, described in roughly the order that they occur, I present the model using pseudocode with the terminology described below. I discuss the issues of assumptions and representations as they arise in describing the model.
7.3.1 Model Representational Assumptions
In order to write a computer program that mirrors the melodic dictation process, how the mind perceives and represents musical information must be defined a priori. Before delving into questions of representation, this model assumes that the musical surface as represented by the notes via Western musical notation are salient and can be perceived as distinct perceptual phenomena Although there is work that suggests that different cultures and levels of experience might not categorize musical information universally (McDermott et al. 2016), other work suggests that experiencing pitches as discrete, categorical phenomena is categorized as a statistical human universal (Savage et al. 2015). In either case, the most explanatory models of any account of music perception should incorporate many features (???). For the purposes of this model, I assume that individuals do in fact perceive the musical surface similarly to the written score.
Knowing that it is melodic information or melodic data that needs to be represented, the question then becomes what is the best way in which to represent it. This issue becomes increasingly complex when considering literature suggesting that the human mind represents musical information in a variety of different forms (Krumhansl 2001; Levitin and Tirovolas 2009). For the purposes of this model and further examples, I choose to represent musical information using both the pitch (note and scale degree) and timing (rhythm and inter-onset-interval) representation described in Pearce (2018). Using these two parameters reflects only a subset of the possibilities that could be modeled when using a multiple viewpoint system (Conklin and Witten 1995). Future research comparing this model’s output using different representations will also contribute to conversations regarding pedagogy. If one form of representation mirrors human behavior better than others, it would provide evidence in support of the pedagogy of one system over another. How the model represents musical information is the first important parameter value that needs to be chosen before running the model and this establishes the Prior Knowledge.
7.3.2 Contents of the Prior Knowledge
The Prior Knowledge consists of a corpus of digitally represented melodies taken to reflect the implicitly understood structural patterns in a musical style that the listener has been exposed to. The logic of representing an individual’s prior knowledge follows the assumptions of both the Statistical Learning Hypothesis (SLH) and the Probabilistic Prediction Hypothesis (PPH), both core theoretical assumptions of the Information Dynamic of Music (IDyOM) model of Marcus Pearce (Pearce 2005, 2018). Using a corpus of melodies to represent an individual’s Prior Knowledge relies on the Statistical Learning Hypothesis which states:
musical enculturation is a process of implicit statistical learning in which listeners progressively acquire internal models of the statistical and structural regularities present in the musical styles to which they are exposed, over short (e.g., an individual piece of music) and long time scales (e.g., an entire lifetime of listening). p.2 (Pearce, 2018)
The logic here is that the more an individual is exposed musical material, the more they will implicitly understand it, which leads the corroborating probabilistic prediction hypothesis which states:
while listening to new music, an enculturated listener applies models learned via the SLH to generate probabilistic predictions that enable them to organize and process their mental representations of the music and generate culturally appropriate responses. p.2 (Pearce, 2018).
Taken together and then quantified using Shannon information content (Shannon 1948), it then becomes possible using the IDyOM framework to have a quantifiable measure that reliably predicts the amount of perceived unexpectedness in a musical melody that can change pending on the musical corpus that the model is trained on. As a model, IDyOM has been successful mirroring human behavior in melodies in various styles (Pearce 2018), harmony– outperforming (Harrison and Pearce 2018) sensory models of harmony (Bigand et al. 2014)–, and is also being developed to handle polyphonic materials (Sauve 2017).
Stepping beyond the assumptions of IDyOM, the Prior Knowledge also needs to have a implicit/explicitly known parameter which indicates whether or not a pattern of music– or n-gram pattern– is explicitly learned. This threshold can be set relative to the entire distribution of all n-grams in the corpus.
7.3.3 Modeling Information Content
Having established that the models’ first parameters to be decided are the representation of strings and the implicit/explicit threshold, the next decision that has to be made is how the model decides segmentation for the second stage of Selective Attention. Although there has been a large amount of work on different ways to segment the musical surface using rule based methods (Lerdahl and Jackendoff 1986; Margulis 2005; Narmour 1990, 1992), which rely on matching a music theorist’s intuition with a set of descriptive rules somewhat like the boundary formation rules put forward in A Generative Theory of Tonal Music, as noted by Pearce (Pearce 2018), rule based models often fail when applied to music outside the Western classical tradition. Additionally, since melodic dictation is an active memory process, rather than a semi-passive process of listening, this model needs to be able to quantify musical information on two conditions. The first is that it must be dependent on prior musical experience. The second is that it should allow for a movable boundary for selective attention so that musical information that is in memory can be actively maintained while carrying out another cognitive process, that of notating the melody.
In order to create this metric, I rely on IDyOM’s use of information content (Shannon 1948), which quantifies the information content of melodies based on a corpus of materials utilizing a multiple viewpoints framework (Conklin and Witten 1995).
For example, when trained against a corpus of melodies, this excerpt in Figure 7.1 from the fourth movement of Schubert’s Octet in F Major (D.803) lists the information content of the excerpt calculated for each note atop the notation6. Appearing in Figure 7.2, I plot the cumulative information content of the melody, along with both an arbitrary threshold for the limits of working memory capacity, and where the subsequent segmentation boundary for musical material to be put in the Selective Attention buffer would be. These values chosen show a small example of how the Selective Attention module works. The advantage of operationalizing how an individual hears a melody like this is that melodies with lower information content, derived from an understanding of having more predictable patterns from the corpus, will allow for larger chunks to be put inside of the selective attention buffer. Additionally, individuals with higher working memory capacity would be able to take in more musical information.

Figure 7.1: Cadential Excerpt from Schubert’s Octet in F Major
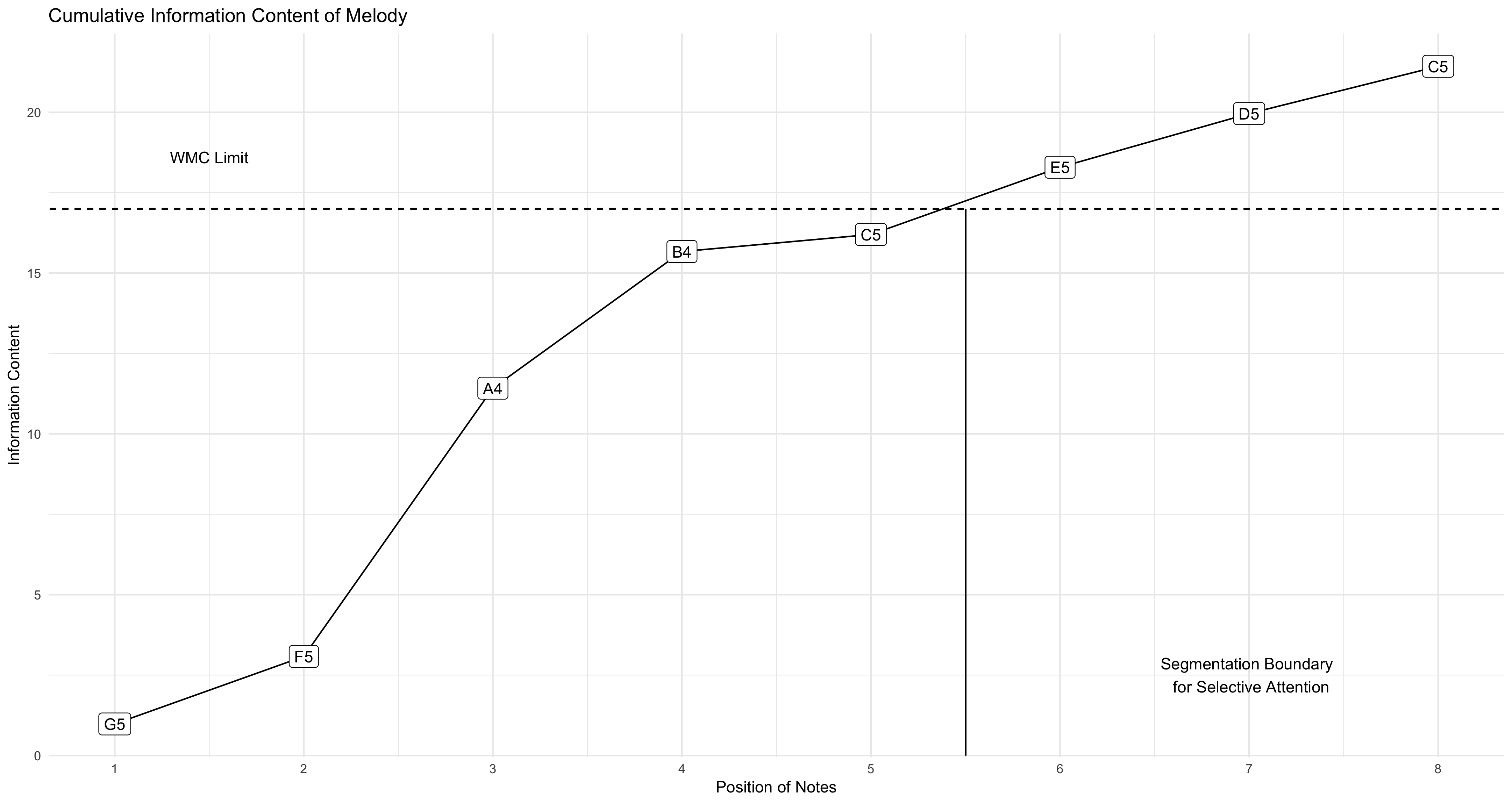
Figure 7.2: Cumulative Information in Schubert Octet Excerpt
It is important to highlight that the notes above the melody here are dependent on what is current in the Prior Knowledge module. A corpus of Prior Knowledge with less musical events would lead to higher information content measures for each set of notes, while a Prior Knowledge that has extensive tracking of the patterns would lead to lower information content (Conklin and Witten 1995). This increase in predictive accuracy mathematically reflects the intuition that those with more listening experience can process greater chunks of musical information. I visualize what setting the explicit/implicit threshold on a set of various n-grams would look like in Figure 7.3. While I have arbitrarily set the thresholds here for illustrative purposes, in practice this could be done a number of different ways. For example, these thresholds could be set based on frequency counts in the corpus, relative distributions, or the parameters might be computationally derived.
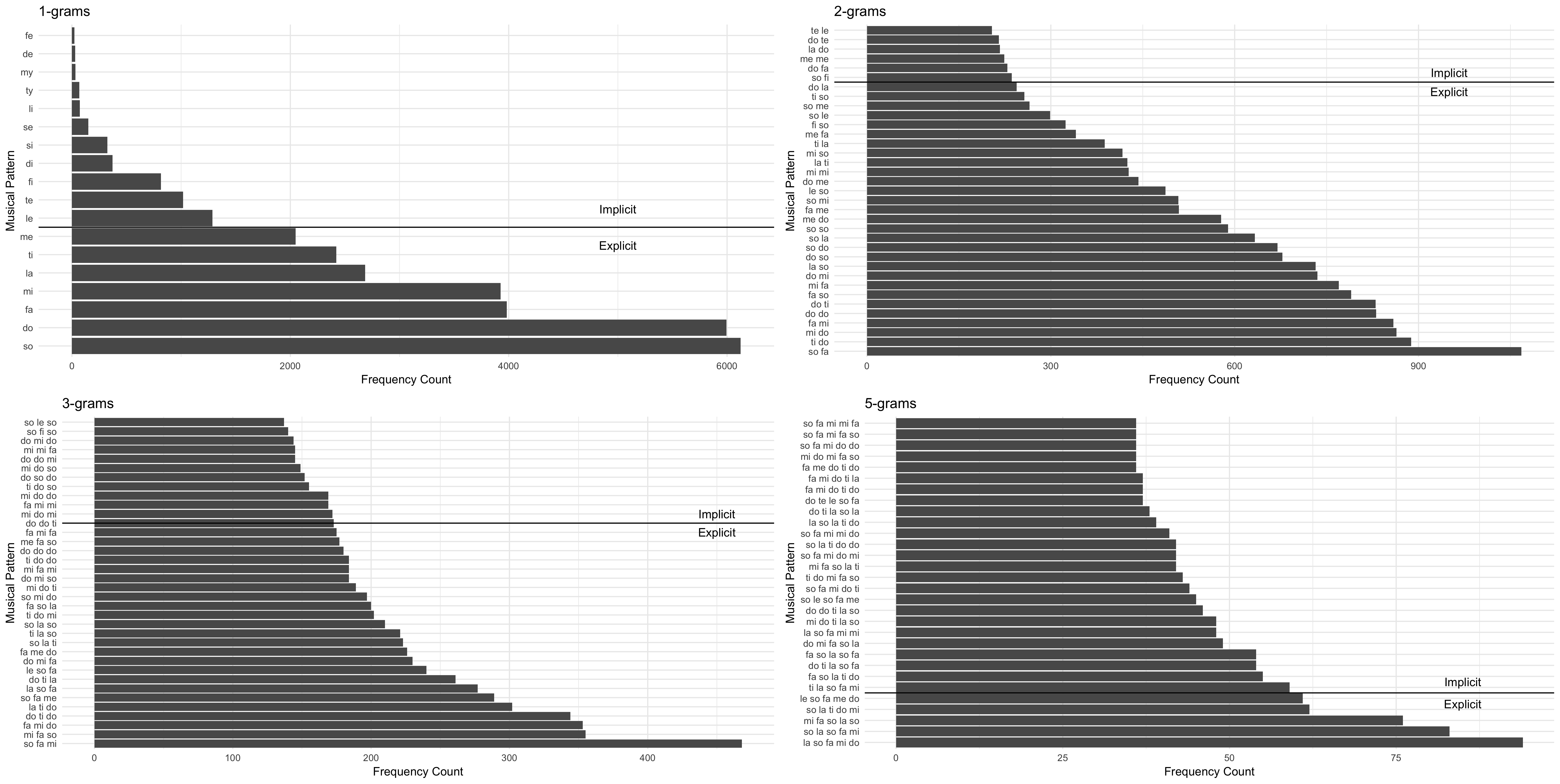
Figure 7.3: Setting Prior Knowledge Limits
7.3.4 Setting Limits with Transcribe
With each note then quantified with a measure of information content, it then becomes possible to set a limit on the maximum amount of information that the individual would be able to hold in memory as defined by the Selective Attention module. A higher threshold would allow for more musical material to be put in the attentional buffer, and a lower threshold would restrict the amount of information held in an attentional buffer. By putting a threshold on this value, this serves as something akin to a perceptual bottleneck based on the assumption that there is a capacity limit to that of working memory (Cowan 1988, 2010). Modulating this boundary will help provide insights into the degree to which melodic material can be retained between high and low working memory span individuals.
In practice, notes would enter the attentional buffer until the information content from the melody is equal to the memory threshold. At this point, the notes that are in the attentional buffer are segmented and will be actively maintained in the Selective Attention buffer. In theory, the maximum of the attentional buffer should not be reached since the individual performing the dictation would still need mental resources and attention to actively manipulate the information in the attentional buffer for the process of notating.
7.3.5 Pattern Matching
The subset of notes of the melody represented in the attentional buffer, whether or not the melody becomes notated depends on whether or not the melody or string in the buffer can be matched with a string that is explicitly known in the corpus. Mirroring a search pattern akin to Cowan’s Embedded Process model (Cowan 1988, 2010), the individual would search across their long term memory, or Prior Knowledge, for anything close to or resembling the pattern in the Selective Attention buffer. Cowan’s model differs from other more modular based models of working memory like those of Baddeley and Hitch (1974) by positing that working memory should be conceptualized as a small window of conscious attention. As an individual directs their attention to concepts represented in their long term memory, they can only spotlight a finite amount of information where categorical information regarding what is in the window of attention is not far from retrieval. Using this logic, longer pattern strings or n-grams would be less likely to be recalled exactly since they occur less frequently in the Prior Knowledge.
If a pattern match that has been moved to Selective Attention is immediately found, the contents of Selective Attention would be considered to be notated. The model would register that a loop had taken place and document the n-gram match. Of course, finding an immediate pattern match each time is highly unlikely, and the model needs to be able to compensate if that happens.
If a pattern is not found in the initial search that is explicitly known, one token of the n-gram would be dropped off the string and the search would happen again. This recursive search would happen until an explicit long term memory match is made. Like humans taking melodic dictation, the computer would succeed more often finding patterns that fall within the largest density of a corpus of intervals distribution. Additionally, like students performing a dictation, if a student does not explicitly know an interval, or a 2-gram, the dictation would not be able to be completed. If this happens, both the model and student would have to move on to the next segment via the Re-entry function.
Eventually there would be a successful explicit match of a string in the Transcription module and that section of the melody would be considered to be dictated. The model here would register that one iteration of the function has been run and the chunk transcribed would then be recorded. After recording this history, the process would happen again starting at either the next note from where the model left off, the note in the entire string with the lowest information content, another pre-determined setting. This parameter is defined before the model is run and the question of dictation re-entry certainly warrants further research and investigation.
This type of pattern search is also dependent on the way that the Prior Knowledge is represented. In the example here, both pitch and rhythmic information are represented in the string that holds the contents of Selective Attention. Since there is probably a very low likelihood of finding an exact match for every n-gram with both pitch and rhythm, this pattern search can happen again with both rhythms and pitch information queried separately. If not found, exact pitch-temporal matches are found and the search is run again on either the pitch or rhythmic information separately. This would be computationally akin to Karpinski’s proto-notation that he suggests students use in learning how to take melodic dictation (Karpinski 2000, 88). This feature of the model would predict that more efficient dictations would happen when pitch and interval information is dictated simultaneously. Running the model prioritizing the secondary search with either pitch or rhythmic information will provide new insights into practical applications of dictation strategies. Using this separate search feature as an option of the model seems to match with the intuitions strategies that a student dictating a melody might use.
7.3.6 Dictation Re-Entry
Upon the successful pattern match of a string, the Selective Attention and Transcription module would need to then be run again. This process is done via the Re-entry function. As noted above, Re-entry in the melody could be a highly subjective point of discussion. The model could either re-enter at the last note where the function successfully left off, the note in the melody with the lowest information content, the n-gram most salient in the corpus, or theoretically any other way that could be computationally implemented. Entering at the last note not transcribed is logical from a computational standpoint, but this linear approach seems to be at odds with anecdotal experience. Entering at the note with the lowest information content seems to provide an intuitive point of re-entry in that it would then be easier to transcribe. Entering at the most represented n-gram seems to align with intuition in that people would want to tackle the easier tasks first, but this rests on the assumption that humans are able to reliably detect the sections of a melody that are easiest to transcribe based on implicitly learned statistical patterns. For example, some people might instead choose to go to the end of a melody after successful transcription of the start of the melody. This might be because this part of the melody is most active in memory due to a recency effect, or it could be that that cadential gestures are more common in being represented in the Prior Knowledge.
7.3.7 Completion
Given the recursive nature of this process, if all 1-grams are explicitly represented in the Prior Knowledge then the target melody will be transcribed. If only represented using such a small chunk, the model will have to loop over the melody many times, thus indicating that the transcriber had a high degree of difficulty dictating the melody. If there is a gap in explicit knowledge in the prior knowledge, only patches of the melody will be recorded and the melody will not be recorded in its entirety. An easier transcription will result in less iterations of the model with larger chunks. Though the current instantiation of the model does not incorporate how multiple hearings might change how a melody is dictated, one could constrain the process to only allow a certain number of iterations to reflect this. Of course as a new melody is learned, it is slowly being introduced into long term memory and could be completely capable of being represented in long term memory without being explicitly notated at the end of a dictation with time running out and thus not possible to be completed. This would be imposing some sort of experimental constraint on the process and since this is meant to be a cognitive computational model of melodic dictation this caveat would complicate the model. Future research could be done to optimize the choices that the model makes in order to satisfy whatever constraints are imposed and could be an interesting avenue of future research, but is beyond the initial goals of the model.
7.3.8 Model Output
The model then outputs each n-gram transcribed and can be counted as a series with less attempts mapping to an easier transcription. This aligns with intuitions about the process of melodic dictation. It first creates a linear mapping of attempts to dictate with difficulty of the melody. It relies on a distinction between explicit and implicit statistical knowledge. It is based on the Embedded Process Model from working memory and attention, so is part of a larger generative model, giving more credibility to explaining the underlying processes of melodic dictation. The output of this model is inspired by work on mental rotation (Shepard and Metzler 1971), which assumes that time to complete a task is directly proportional to cognitive effort required. More iterations of the model as reflected in more searches should reflect more mental effort and vice versa.
7.4 Formal Model
I present the computational model in pseudocode as described in Figure 7.4. First, listed are the defined inputs, the functions needed to run the algorithm, and then the sequence the model runs. To aid distinguishing between functions and objects, I put functions in italics and objects in bold. Below the model in Figure 7.5 I provide a brief walk through of one iteration of the model.
7.4.1 Computational Model

Figure 7.4: Formal Model
7.4.2 Example
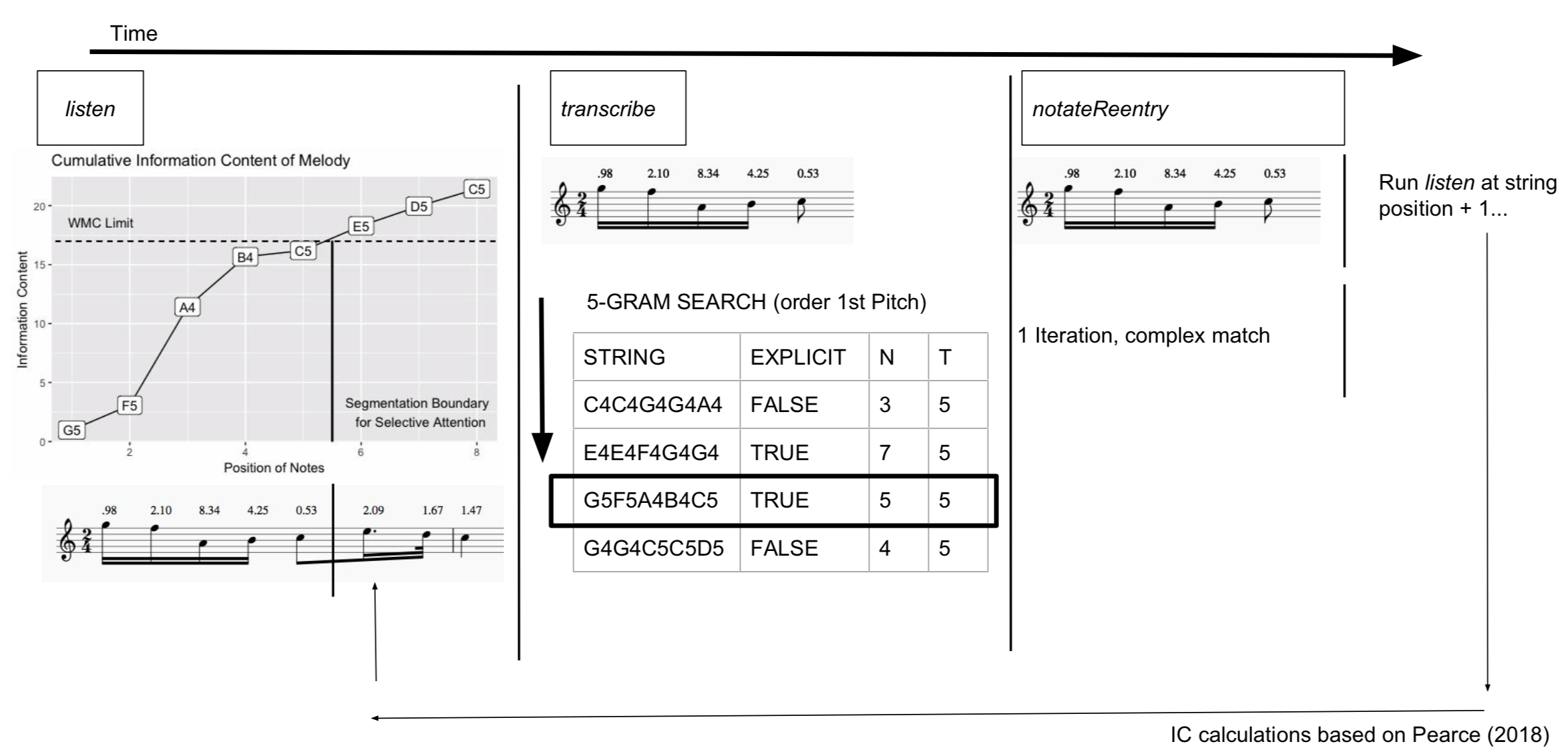
Figure 7.5: Model Example
Figure ?? depicts one iteration of the model run using the musical example from above using a hypothetical corpus for the pattern matching. Using the model above, the following inputs were defined a priori:
- The Prior Knowledge is a hypothetical corpus of symbolic strings representing all n-grams of melodies
- The Threshold is set to five exact matches in the Prior Knowledge
- The WMC is set at 17
- The Target Melody is the Schubert excerpt from above
- The String Position object is used to track the position in the dictation
- The Difficulty object starts at 0
- The Dictation object is
NULLto begin, and each new n-gram successfully transcribed is annexed to it
Figure 7.5 progresses from left to right over the course of time.
The algorithm begins by first running the listen() function on the Target Melody.
First, the model checks that there are notes to transcribe; this being the first loop of the model, this is statement will be FALSE so the next step is taken.
Notes of the Target Melody are read in to the Selective Attention buffer until the information content of the melody exceeds that of the working memory threshold.
This is depicted graphically in the leftmost panel of Figure 7.5.
Each note unfolding over time fills up the Selective Attention working memory buffer.
When the amount of information reaches the perceptual bottleneck– as indicated by the dashed line– the Selective Attention buffer stops receiving information.
At this point the model will mark where in the melody it stopped taking in new information for later.
Here the contents in Selective Attention are moved to the transcribe() function.
With the contents of Selective Attention passed to transcribe(), the model adds one to the counter indicating the first search is about to run.
Moving to the middle panel of Figure 7.5, the symbol string of notes in the first column is indexed against the Prior Knowledge.
Only if a five note pattern has appeared more than or equal to five times, as determined by the Threshold input, will the corresponding EXPLICIT column be TRUE.
In this case, this pattern has occurred over the threshold of 5 and thus a successful match is found.
It is at this step that the search resembles that of Cowan’s model of working memory as active attention.
The pattern being searched for is compared against a vast amount of information, with cues from the contents of what is in Selective Attention grouping similar patterns together.
At the neural level, this is most likely a much more complex process, but to show this grouping I note that this search is at least organized by the first pitch.
I assume it would be reasonable that patterns starting on G as \(\hat{5}\) might happen together.
Since this string does have a TRUE match with EXPLICIT, the contents of Selective Attention are considered notated.
At this point the model would record the 5-gram, along with the string that it was matched with.
The function would then re-run the listen function via the notateReentry() function at the next point in the melody as tracked by the String Position object.
If there were not to have been an exact match, the model would remove one token from the melody and perform the search again on the knowledge of all 4-grams and add one to the Difficulty counter.
This process would happen recursively until a match is found.
If no match is found in either the complex representation, or that of the two rhythm and pitch corpora, the fifth step of transcribe() would trigger notateReentry() to be run without documenting the n-gram currently being dictated.
This would be akin to a student not being able to identify a difficult interval, thus having to restart the melody at a new position.
Decisions about re-entry warrant further research and discussion, but for the sake of parsimony this model assumes linear continuation.
As notated in Dictation Re-Entry, other modes of re-entry could be incorporated into the model.
This looping process would occur again and again until the entire melody is notated.
With each iteration of each n-gram notated, the difficulty counter would increase in relation to the representation of that string in the corpus.
This provides an algorithmic implementation of the intuition that less common n-grams or intervals (2-grams) are going to lead to higher difficulty in dictation.
Also worth noting is steps 3 and 4 in the transcribe() function are akin to Karpinski’s proto-notation.
Further research might consider advantages in the order of searching the Prior Knowledge corpora.
7.5 Conclusions
In this chapter, I presented an explanatory, computational model of melodic dictation. The model combines work from computational musicology and work from cognitive psychology. In addition to being a complete model that explicates every step of the dictation process, the model seems to match phenomenological intuitions as to the process of melodic dictation. Given the current state of the model, it makes predictions about the dictation process and can eventually be implemented and tested against human behavioral data to provide evidence in support of its verisimilitude. For example, the model predicts:
- Segments of melodies are likely successfully to be dictated relative to the frequency distribution of their prior knowledge.
- Higher working memory span individuals will be able to dictate larger chunks of melodies, and thus perform better at dictation
- Using an atomistic dictation strategy will result in not as effective dictations than attempting to identify larger patterns
- Determining the difficulty of melodies of equal length is predictable from the frequency the melody’s cumulative n-gram distribution.
- Some atonal melodies will be easier to dictate than tonal melodies if they consist of patterns that are more frequent in a listener’s Prior Knowledge.
- Higher exposure to sight-singing results in more explicitly learned patterns, thus the ability to identify larger patterns of music
Although many of these hypotheses might seem intuitive to any instructor who has taught aural skills before, work from this dissertation provides a theory as to why each appears to be true. Future research beyond this dissertation will explore predictions as a result of this work in more detail. Most importantly from a pedagogical standpoint, the model and underlying theory gives exact language to discuss the underlying processes of melodic dictation, which can serve as a valuable pedagogical and research contribution.
References
Wiggins, Geraint A. 2007. “Models of Musical Similarity.” Musicae Scientiae 11 (1_suppl): 315–38. https://doi.org/10.1177/102986490701100112.
Pearce, Marcus T. 2018. “Statistical Learning and Probabilistic Prediction in Music Cognition: Mechanisms of Stylistic Enculturation: Enculturation: Statistical Learning and Prediction.” Annals of the New York Academy of Sciences 1423 (1): 378–95. https://doi.org/10.1111/nyas.13654.
Saffran, Jenny R, Elizabeth K Johnson, Richard N Aslin, and Elissa L Newport. 1999. “Statistical Learning of Tone Sequences by Human Infants and Adults.” Cognition 70 (1): 27–52. https://doi.org/10.1016/S0010-0277(98)00075-4.
Margulis, Elizabeth Hellmuth. 2014. On Repeat: How Music Plays the Mind. Oxford: Oxford University Press.
Huron, David. 2006. Sweet Anticipation. MIT Press.
Karpinski, Gary Steven. 2000. Aural Skills Acquisition: The Development of Listening, Reading, and Performing Skills in College-Level Musicians. Oxford University Press.
Karpinski, Gary. 1990. “A Model for Music Perception and Its Implications in Melodic Dictation.” Journal of Music Theory Pedagogy 4 (1): 191–229.
Pearce, Marcus. 2005. “The Construction and Evaluation of Statistical Models of Melodic Structure in Music Perception and Composition.” PhD thesis, Department of Computer Science: City University of London.
Cowan, Nelson. 1988. “Evolving Conceptions of Memory Storage, Selective Attention, and Their Mutual Constraints Within the Human Information-Processing System.” Psychological Bulletin 104 (2): 163–91.
Cowan, Nelson. 2010. “The Magical Mystery Four: How Is Working Memory Capacity Limited, and Why?” Current Directions in Psychological Science 19 (1): 51–57. https://doi.org/10.1177/0963721409359277.
Lerdahl, Fred, and Ray Jackendoff. 1986. A Generative Theory of Tonal Music. Cambridge: MIT Press.
Narmour, Eugene. 1990. The Analysis and Cognition of Basic Melodic Structures: The Implication-Realization Model. Chicago: University of Chicago Press.
Narmour, Eugene. 1992. The Analysis and Cognition of Melodic Complexity: The Implication-Realization Model. University of Chicago Press.
Temperley, David. 2004. The Cognition of Basic Musical Structures. Cambridge: MIT Press.
McDermott, Josh H., Alan F. Schultz, Eduardo A. Undurraga, and Ricardo A. Godoy. 2016. “Indifference to Dissonance in Native Amazonians Reveals Cultural Variation in Music Perception.” Nature 535 (7613): 547–50. https://doi.org/10.1038/nature18635.
Savage, Patrick E., Steven Brown, Emi Sakai, and Thomas E. Currie. 2015. “Statistical Universals Reveal the Structures and Functions of Human Music.” Proceedings of the National Academy of Sciences 112 (29): 8987–92. https://doi.org/10.1073/pnas.1414495112.
Krumhansl, Carol. 2001. Cognitive Foundations of Musical Pitch. Oxford University Press.
Levitin, Daniel J., and Anna K. Tirovolas. 2009. “Current Advances in the Cognitive Neuroscience of Music.” Annals of the New York Academy of Sciences 1156 (1): 211–31. https://doi.org/10.1111/j.1749-6632.2009.04417.x.
Conklin, Darrell, and Ian H. Witten. 1995. “Multiple Viewpoint Systems for Music Prediction.” Journal of New Music Research 24 (1): 51–73. https://doi.org/10.1080/09298219508570672.
Shannon, Claude. 1948. “A Mathematical Theory of Communication.” Bell System Technical Journal 27: 379–423.
Harrison, Peter M . C., and Marcus Thomas Pearce. 2018. “Dissociating Sensory and Cognitive Theories of Harmony Perception Through Computational Modeling.” https://doi.org/10.31234/osf.io/wgjyv.
Bigand, Emmanuel, Charles DelbÃ, BÃnÃdicte Poulin-Charronnat, Marc Leman, and Barbara Tillmann. 2014. “Empirical Evidence for Musical Syntax Processing? Computer Simulations Reveal the Contribution of Auditory Short-Term Memory.” Frontiers in Systems Neuroscience 8 (June). https://doi.org/10.3389/fnsys.2014.00094.
Sauve, Sarah. 2017. “Prediction in Polyphony: Modelling Auditory Scene Analysis.” PhD thesis, Centre for Digital Music: Queen Mary, University of London.
Margulis, Elizabeth Hellmuth. 2005. “A Model of Melodic Expectation.” Music Perception: An Interdisciplinary Journal 22 (4): 663–714. https://doi.org/10.1525/mp.2005.22.4.663.
Baddeley, Alan D., and Graham Hitch. 1974. “Working Memory.” In Psychology of Learning and Motivation, 8:47–89. Elsevier. https://doi.org/10.1016/S0079-7421(08)60452-1.
Shepard, R. N., and J. Metzler. 1971. “Mental Rotation of Three-Dimensional Objects.” Science 171 (3972): 701–3. https://doi.org/10.1126/science.171.3972.701.
The following musical examples is taken from Pearce (2018) reflects a model where IDyOM was configured to predict pitch with an attribute linking melodic pitch interval and chromatic scale degree (pitch and scale degree) using both the short-term and long-term models, the latter trained on 903 folk songs and chorales (data sets 1, 2, and 9 from table 4.1 in (Schaffrath 1995) comprising 50,867 notes.↩