Chapter 4 Computation Chapter
4.1 Rationale
Music theorists use their experience and intuition to build appropriate curricula for their aural skills pedagogy. Teaching aural skills typically starts with providing students with simpler exercises, often employing a limited number of notes and rhythms, and then slowly progressing to more difficult repertoire. This progression from simpler to more difficult exercises is evident in aural skills textbooks. Of the major aural skills textbooks such as the Ottman and Rogers (2014), Berkowitz (2011), Karpinski (2007), and Cleland and Dobrea-Grindahl (2010), each is structured in a way that musical material presented earlier in the book is more manageable than that nearer the end. In fact, this is true of almost any étude book: open to a random page in a book of musical studies and the difficulty of the study will likely scale accordingly to its relative position in the textbook. But it is not a melody’s position in a textbook that makes it difficult to perform: this difficulty comes from the structural elements of the music itself.
Intuitively, music theorists have a general understanding of what makes a melody difficult to dictate. Factors that might contribute to this complexity could range from the number of notes in the melody, to the intricacies of the rhythms involved, to the scale from which the melody derives, to even more intuitively understood factors such as how tonal the melody sounds. Although given all these factors, there is no definitive combination of features that perfectly predicts the degree to which pedagogues will agree how complex a melody is. In many ways, questions of melodic complexity are very much like questions of melodic similarity: it depends on both who is asking the question and for what reasons (Cambouropoulos 2009).
Examining the melodies presented in Figures 4.1 and 4.2, most aural skills pedagogues will be able to successfully intuit which melody is more complex, and presumably, more difficult to dictate.

Figure 4.1: A Musical Puzzle
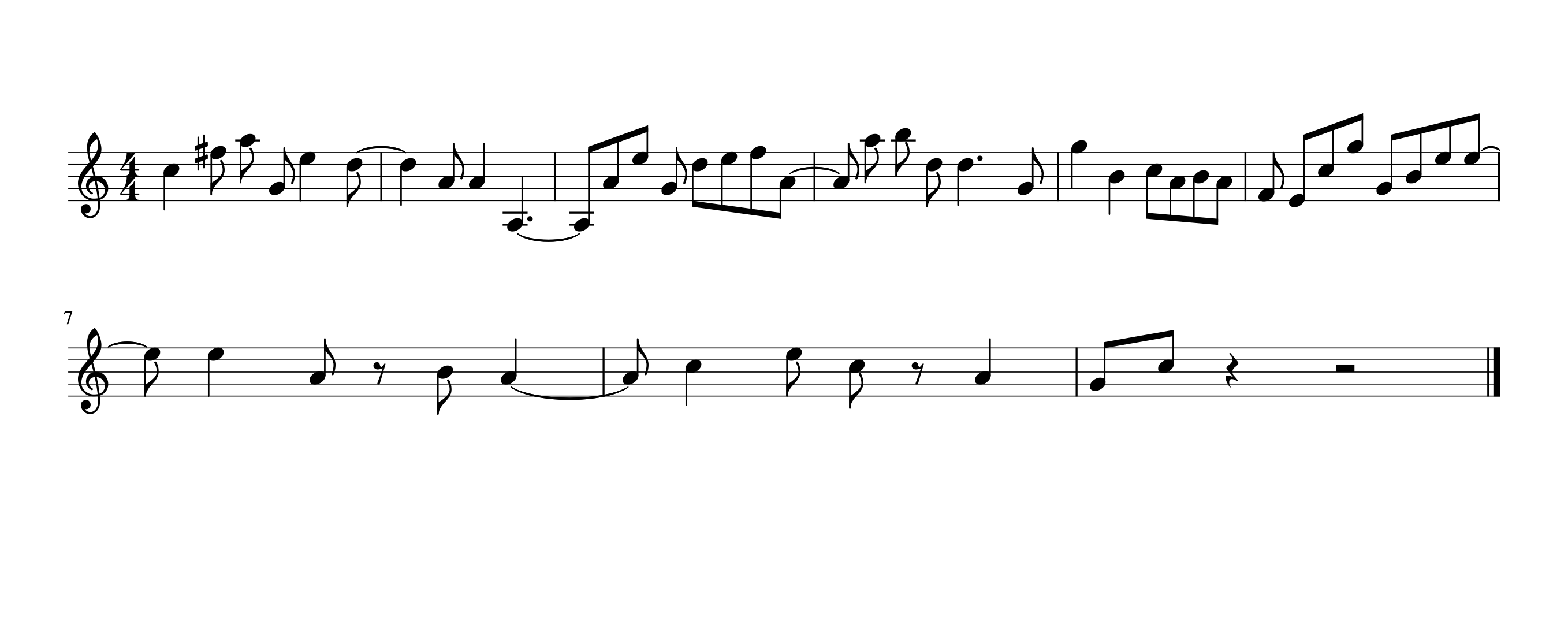
Figure 4.2: B Musical Puzzle
While I reserve an extended discussion of what features might characterize why one melody is more difficult to dictate than the other for this chapter, I assume that these melodies differ in their ability to be dictated in some fundamental way when performed in a similar fashion. Additionally, many readers of this dissertation can draw from anecdotal evidence of their own as to how students at various stages of their aural training might fair when asked to dictate both melodies. For some, Melody 4.2 might be overwhelmingly difficult.
In fact, Melody 4.2 might be overwhelmingly difficult for the vast majority of musicians to dictate. From a pedagogical standpoint, educators need to be able to know how difficult melodies are to dictate in order to ensure a degree of fairness when assessing a student’s performance. While of course with each student there are inevitably many variables at play in aural skills instruction ranging from personal abilities, to the goals of the instructor in the scope of their course, I find it fair to claim that pedagogues assume that students will be expected to pass pre-established benchmarks throughout their aural skills education. As students progress, they are expected to be able to dictate more difficult melodies, yet exactly what makes a melody complex and thus difficult to dictate is often left to the expertise and intuition of a pedagogue. Intuition is an important skill for teachers to cultivate, but when it comes to determining objective measures of judgment, research from decision making science tends to suggest that no matter the expertise, collective and objective knowledge tends to outperform a single person’s judgment (Kahneman 2012; Logg, Minson, and Moore 2019; Meehl 1954). Having more clearly defined performance benchmarks also helps remove biases in grading that teachers may or may not be explicitly aware of. Recent research has suggested that even aural skills pedagogues are open to the idea of looking for more standardization in aural skills assessments (Paney and Buonviri 2014).
In this chapter, I survey and examine how tools from computational musicology can be used to help model an aural skills pedagogue’s notion of complexity in melodies. First, I establish that theorists agree on the differences in melodic complexity using results from a survey of 40 aural skills pedagogues. Second, I explore how both static and dynamic computationally derived abstracted features of melodies can and cannot be used to approximate an aural skills pedagogue’s intuition. Third and finally, I use evidence afforded by research in computational musicology to posit that the distributional patterns in a corpus of music can be strategically employed to create a more linear path to success among students of aural skills. I demonstrate how combining evidence from the statistical learning hypothesis, the probabilistic prediction hypothesis, and a newly posited distributional frequency hypothesis, it is possible to explain why some musical sequences in a melody are easier to dictate than others. Using this logic, I then create a new compendium of melodic incipits, sorted by their perceptual complexity, that can be used for teaching applications.
4.2 Agreeing on Complexity
Returning to melodies 4.1 and 4.2 from above, an aural skills pedagogue most likely has an intuition to which of the two melodies X or Y would be easier to dictate. Melody 4.1 exhibits a predictable melodic syntax and phrase structure, the chromatic notes resolve within the conventions of the Common Practice period, and the melody itself could be scored with tertian harmony. On the other hand, Melody 4.2’s syntax does not conform to the conventions of the Common Practice period and does not imply any sort of underlying harmony or predictiable phrase rhythm. The duration of the rhythms appear irregular and the melody implies an uneven phrase structure. Yet both melodies 4.1 and 4.2 have the exact same set of notes and rhythms. Despite these content similarities, it would be safe to assume that melody 4.1 is probably much easier to dictate than melody 4.2 assuming both were to be played in a similar fashion.
In fact, aural skills pedagogues tend to agree for the most part on questions of difficulty of dictation. To demonstrate this, I surveyed 40 aural skills pedagogues who all have taught aural skills at the post-secondary level. In this survey, participants were asked the questions presented in Table ?? and Table ?? using a sample of 20 melodies found in the a commonly used sight-singing text book (Berkowitz 2011). I present the details of the survey below.
4.2.1 Methods
To select the melodies used in this survey, I randomly sampled 30 melodies from a corpus of melodies (N = 481) from a subset of the Fifth Edition of the Berkowitz “A New Approach to Sight Singing” (Berkowitz 2011) in order to ensure a representative sampling of melodies that might be used in a pedagogical setting. After piloting the randomly sampled melodies on a colleague, I again randomly sampled half of this sub-set and then added in five more melodies that were not in the new set from earlier sections of the book in order to be more representative of materials students might find in the first two semesters of their aural skills pedagogy. I ran the survey from January 31st of 2019 until March 7th, 2019. The survey comprised of two sets of questions.
Six questions asked about the teaching background of respondents and can be found in ??. These questions were followed by asking participants to make five ratings over the 20 different melodies. The five questions can be found in ??. To encourage participation, two $30 cash prize were offered to two participants. The survey had questions that were specifically designed to gauge their appropriateness for use in a melodic dictation context. Participants were recruited exclusively online and all provided consent to partaking in the data collection as approved by the Louisiana State University Institutional Review Board.
The table below contains the questions used in the demographic questionnaire. Examples were given following each questions and can be found on the survey link.
| Demographic.Questions |
|---|
| What is your age, in years? |
| What is your educational status? |
| How many years have you been teaching Aural Skills at the University level? |
| Which type of syllable system do you prefer to use? |
| On which instrument have you gained the most amount of professional training? |
| What is the title of the last degree you received? |
| At what institution are you currently teaching? |
The table below contains the questions regarding the ratings of the melodies. Participants either responded using ordinal categories or moved a slider that sat atop a 100 point scale. The survey can be found at https://musiccog.lsu.edu/dictation_survey/aural_survey.html.
| Item.Questions |
|---|
| During which semester of Aural Skills would you think it is appropriate to give this melody as a melodic dictation? |
| How many times do you think this melody should be played in a melodic dictation considering the difficulty you noted in your previous question? Assume a reasonable tempo choice from 70-100BPM. |
| Please rate how difficult you believe this melody to be for the average second-year undergraduate student at your institution. The far left should indicate ‘Extremely Easy’ and the far right should indicate ‘Extremely Difficult’. |
| Please rate this melody’s adherence to the melodic grammar of the Common Practice Period. The far left should indicate ‘Not Well Formed’ and the far right should indicate ‘Very Well Formed’. |
| Is this melody familiar to you? |
Of the respondents, the average amount of years teaching aural skills was 8.76 years (\(SD = 7.60, R: 21-29\)). I plotted the breakdown of the respondent’s age and educational status below in Figure 4.3. Of the 40 respondents, all reported used some sort of movable system other than 2 who used a fixed system. The sample represented over 30 different institutions. Overall, the sample reflects a wide range of experience of teaching aural skills. The sample contains both younger and older individuals, as well as a range of experience. In the Figures 4.4 through ?? below, I list the 20 melodies sampled.
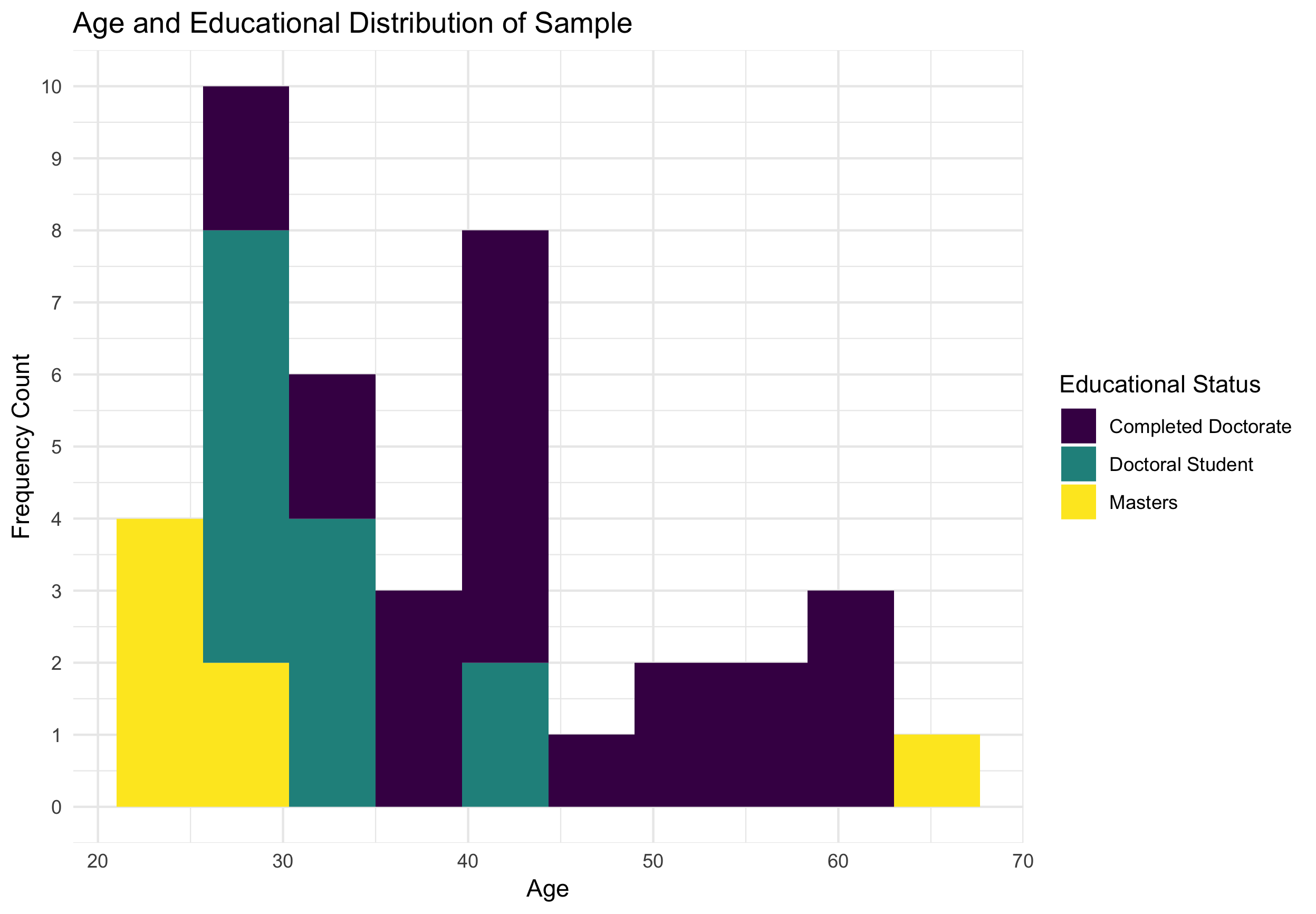
Figure 4.3: Demographic Breakdown of Sample

Figure 4.4: Melody 3 | Rank 1

Figure 4.5: Melody 9 | Rank 2

Figure 4.6: Melody 26 | Rank 3

Figure 4.7: Melody 59 | Rank 4

Figure 4.8: Melody 70 | Rank 5

Figure 4.9: Melody 74 | Rank 6

Figure 4.10: Melody 75 | Rank 7

Figure 4.11: Melody 88 | Rank 8

Figure 4.12: Melody 156 | Rank 9

Figure 4.13: Melody 282 | Rank 10

Figure 4.14: Melody 294 | Rank 11

Figure 4.15: Melody 312 | Rank 12

Figure 4.16: Melody 334 | Rank 13
Figure 4.17: Melody 379 | Rank 14

Figure 4.18: Melody 382 | Rank 15

Figure 4.19: Melody 417 | Rank 16

Figure 4.20: Melody 607 | Rank 17

Figure 4.21: Melody 622 | Rank 18

Figure 4.22: Melody 627 | Rank 19

Figure 4.23: Melody 629 | Rank 20
4.2.2 Agreeing on Difficulty
In order to assess the degree to which pedagogues agreed on a melody for melodic dictation, I first plotted the mean ratings for each melody across the entire sample along with their standard error of the means in Figure 4.24. The \(x\) axis uses the rank of the melodies, not their index position in the Berkowitz textbook. I chose to use this rank order metric as the number of a melody in a textbook is presumed to be best conceptualized as an ordinal variable. For example, it would be correct to assume that Melody 200 is more difficult than melody 2, but not by a factor of 100.
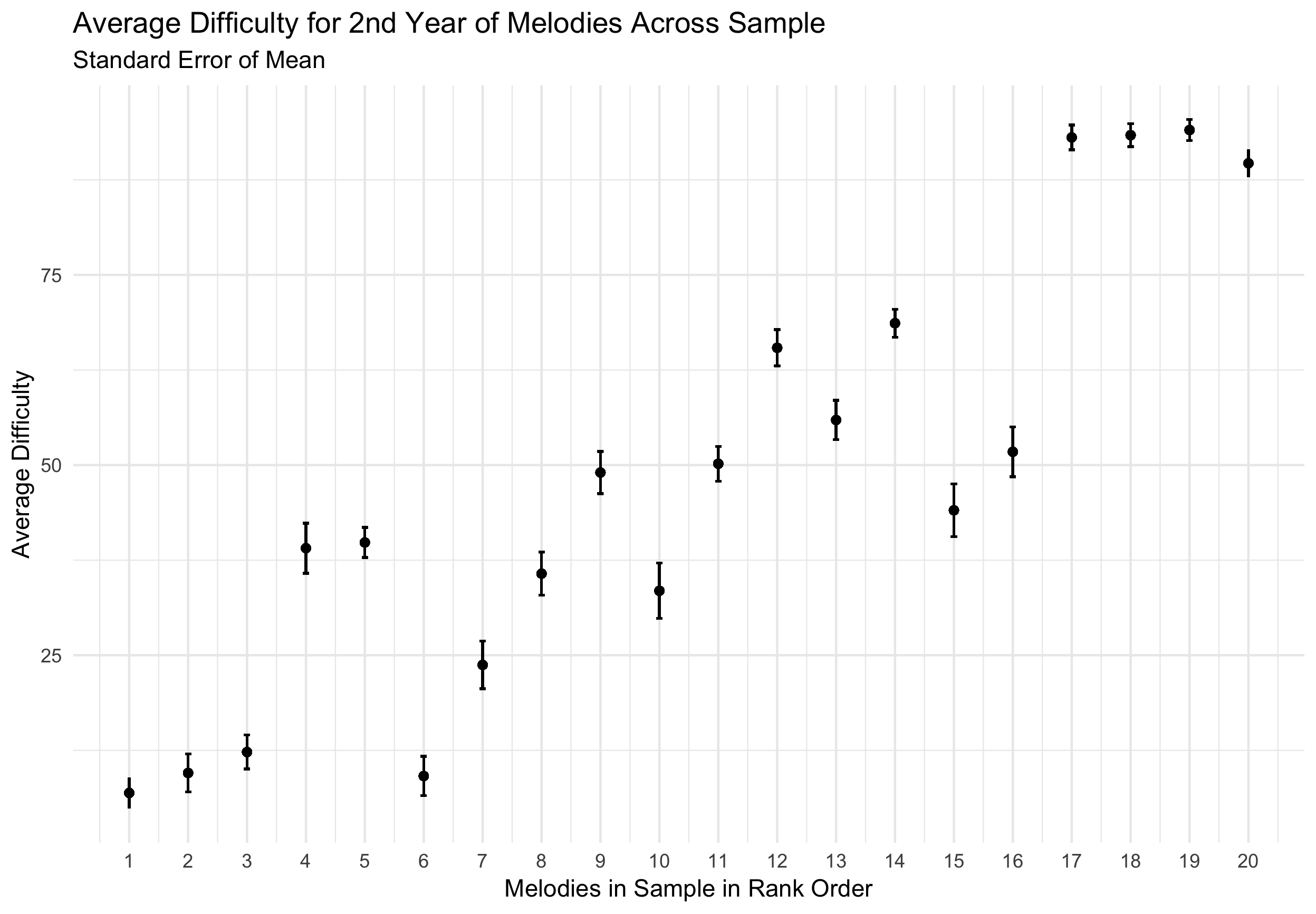
Figure 4.24: Average Difficulty
From Figure 4.24, there is an increasing linear trend from ratings of melodies being less difficult to more difficult across the sample. Using an intraclass coefficient calculation of agreement using a two-way model (both melodies and raters treated as random effects), the sample reflects an interclass correlation coefficeint of .79. According to Koo and Li (2016), this reflects a good degree of agreement between raters. This trend across the sample appears in the opposite direction when plotting the mean values to the fourth question in Figure 4.25 from the survey reflecting the melody’s adherence to the melodic grammar of the Common Practice period.
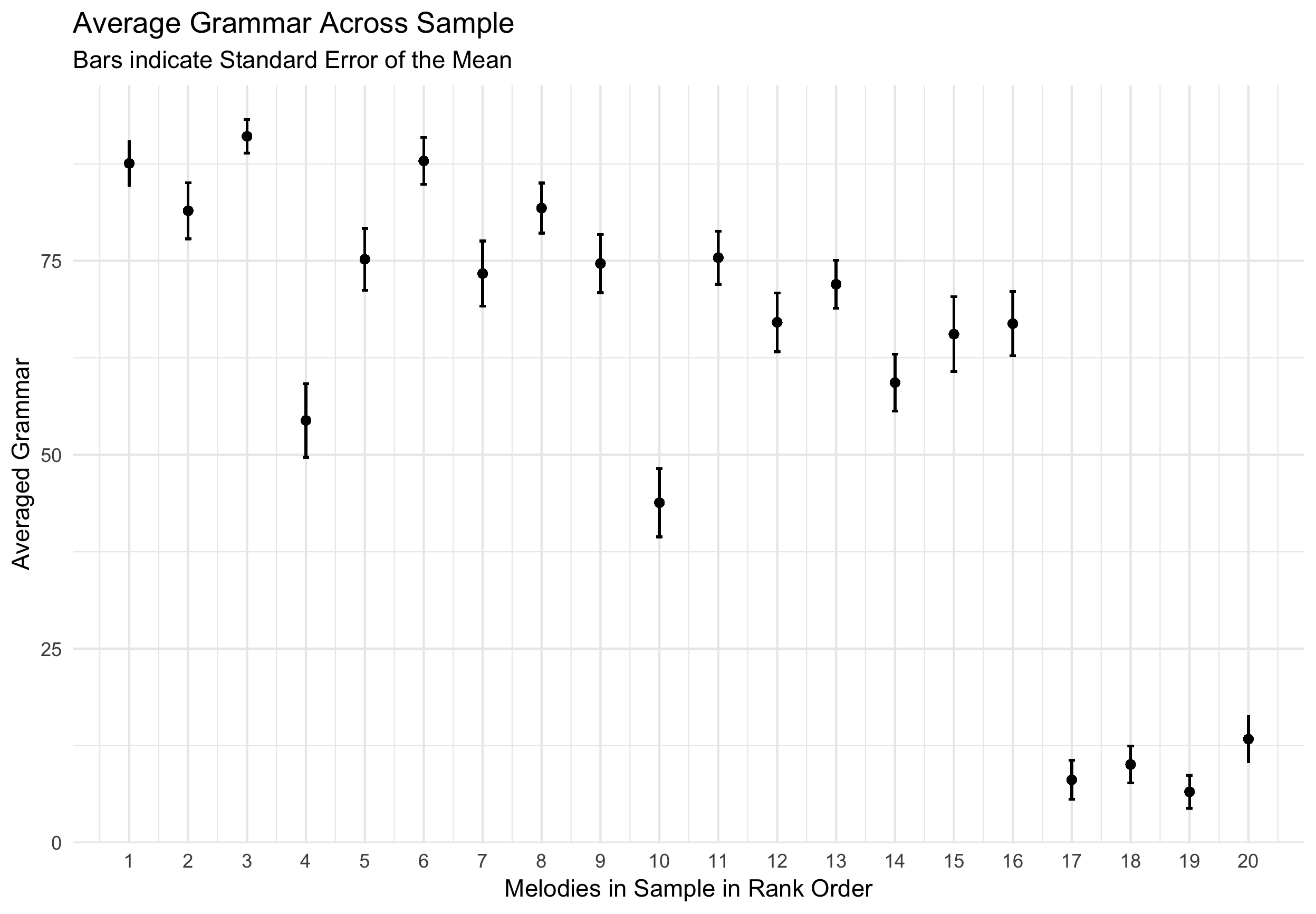
Figure 4.25: Average Grammar Ratings
While similar trends appear here, yet in the opposite direction as expected, there is a clear breaking of linear trend in the far right potion of the graph that shows melodies that were sampled from the chapter of the corpus that contains atonal melodies. Using an intraclass coefficient calculation of agreement using a two-way model, with melodies and raters treated as random effects, the sample reflects an interclass coeffiecent of .65, which according to Koo and Li (2016) indicates a moderate degree of agreement among raters. This lower agreement rating is most likely due to the subjectiveness of this question. In their free text responses, many participants expressed difficulty in surmising what this meant.
The trends from Figure 4.24 and Figure 4.25 occur in the opposite direction. As the index or rank of the melody increases, so does the difficulty for the rating as would be expected. As the index or rank of the melody increases, its adherence to subjective ratings of melodic grammar of the Common Practice period decreases. Taken together, I ran a correlation on every one of the twenty melodies between a single rater’s judged difficulty and its judged adherence to tonal expectations of the common practice era. The correlations for all 20 melodies are plotted here in Figure 4.26. From this chart, we see this trend is not uniform across all melodies.
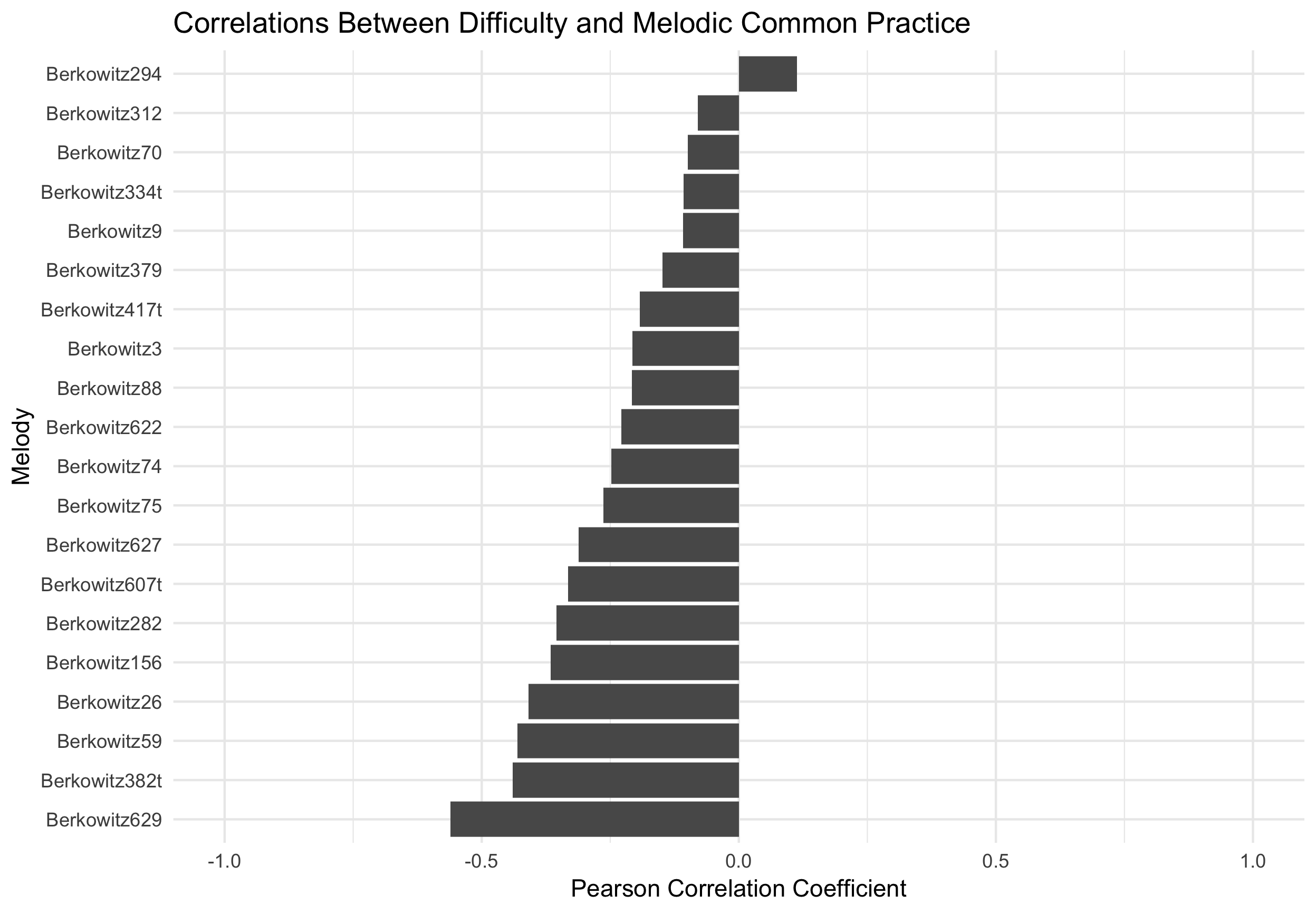
Figure 4.26: Strength of Relationship Between Difficulty and Subjective Tonal Grammar
Overall, the sample exhibited an acceptable degree of inter-rater reliability as measured by the interclass correlation coefficient. Plotting the respondent’s answers across the textbook that melodies were taken from, with the book progressing from less to more difficult, it does appear that aural skills pedagogues tend to agree on how difficult a melody is when used in a dictation setting.
Central to my argument, there appears to a linear trend of difficulty across the sample based on the melodies rank in the sample. In fact, although I presented the data above as ordinal using rank in the textbook, when I ran a mixed-effects linear regression predicting melody difficulty with both rank order as a variable as well as the actual index number of the melody from the Berkowitz, the index model significantly outperforms the rank order model. Using the lme4 package (Bates et al. 2015), I fit two linear mixed effects models predicting difficulty of melody with subject and item both as random effects in the model, with the only difference in models being a melody rank or melody index. When comparing models, the index model (BIC = 6706.3) provided a better fit to the data (\(\chi^2\)=5.38, \(p<.05\)) than the rank model (BIC = 6711.7).
Taken together, both anecdotal and empirical evidence for this survey suggest that aural skills pedagogues tend to agree on how difficult a melody is for use in an aural skills setting. This sense of difficulty or complexity tracks as the book progresses, but to attribute the cause of a melody being difficult as its position in the book would be putting the cart before the horse. Having now formally established this almost intuitive notion, the remaining portion of this chapter investigates how computationally derived tools can be used to model these commonly held intuitions. In order to provide a sense of validity to the measure, I carry forward ratings from the survey reported and use the expert answers as the ground truth for the the resulting models.
4.3 Modeling Complexity
The ability to quantify what theorists generally agree to be melodic complexity depends on distilling complexity into its component parts. Earlier, when comparing melodies X and Y, some of the features put forward that might contribute to complexity were features such as note density, the melody’s rhythm, what scale the melody draws its notes from, and how tonal the melody might be perceived. Some combination of these component features presumably make up the construct of complexity.
Attempting to use features of a melody to to predict how well a melody is remembered has a long history. In 1933, Ortmann put forward a set of melodic determinants that he asserted predicted how well a melody was remembered. These features such as a melody’s repetition, pitch-direction, contour (conjunct-disjunct motion), degree, order, and implied harmony (chord structure) were deemed to affect the melody’s ability to be remembered (Ortmann 1933).
Since Ortmann, pedagogues such as Taylor and Pembrook have expanded on this research, finding significant effects of musical features such as length, tonality, as well as type of motion as well as an effect of experimental condition (Taylor and Pembrook 1983). Following up on Taylor’s investigation, Pembrook (1986) found evidence corroborating Ortmann’s initial claims that his four major determinants (repetition, note direction, conjunct-disjunct motion, degree of disjunctivness) had a significant main effects on an individual’s ability to take dictation, yet note that these values do not exhaustively explain the findings. In their discussion, they also note the problems of completely isolating the effects of certain musical features as when you change one parameter, others are also subject to change. When looking at changes in structural elements of melodies, there is a collinearity issue among features. Not only does this problem exist within features of melodies, but also among participants. In reflecting on other factors that might contribute to their results, the authors note
Clearly, a complete hierarchy of determinants would constitute a very long list, because not only would the many melodic structures be included, but also their interactions with subject and environmental variables. The ones included in the present study (musical experience, melodic carryover, and response method) provided evidence that the melodic determinants are not constant; rather, they vary as a function of the subject and environmental factors, which in turn can have significant effects on music discrimination and memory. (p. 33)
The authors later in the article go on to stress that future work should both replicate their findings as well as expand their modeling parameters. They call for a larger sample, a broader spectrum of musical experiences, and to investigate more musical features.
Since then, some, but not many researchers, have employed using features of the melodies to predict a behavioral measure in experimental settings. Not using as extensive of a battery as Ortman, Taylor, or Pembrook, researchers in music psychology such as as Akiva-Kabiri et al. (2009), Dewitt and Crowder (1986), Eerola, Louhivuori, and Lebaka (2009), Schulze and Koelsch (2012) have used the number of notes in a melody as a successful predictor of difficulty in melodic perception and discrimination tasks. Expanding on just using frequency of note counts, Harrison, Musil, and Müllensiefen (2016) instead of looking at single measures of melodic complexity, addressed the melodic collinearity issue noted by Taylor and Pembrook by using data reductive techniques to derive a single complexity measure found to be predictive in their statistical modeling deriving these measures from the FANASTIC toolbox (Mullensiefen 2009). Following this research, Baker and Müllensiefen (2017) also incorporated a similar measure of complexity in their model of leitmotiv recognition in which they predicted recall rates in a recognition paradigm.
Each of these examples operationalizes some feature of the melody with a quantitative, numerical proxy that is assumed to be able to be mapped to perception. Ortman referred to these as determinants, while others such as Müllensiefen refer to them as features (Mullensiefen 2009). Since the word feature refers to a ‘distinctive attribute’, I will use this terminology throughout the rest of the chapter, though note that other terms have been used.
4.3.1 What Are Features?
A feature can be either a quantitative or qualitative observable feature of a melody that is assumed to be perceptually salient to the listener. Features are often difficult to quantify with the traditional tools of music analysis. Often, these features come inspired from other domains like computational linguistics.
The nPVI began as a measure of rhythmic variability in language (Grabe 2002). Shown below, the nPVI quantifies the amount of durational variability in language. It works by comparing the variability of vowel length compared to syllable length
\[nPVI = 100 * [\sum_{k=1}^{m-1} | \frac{d_k - d_{k+1}}{(d_k + d_{k+1})/2}/(m-1)] \]
where \(M\) is the number of vowels in an utterance and \(d_k\) is th duration of the \(k^{th}\) item and has been used in musical contexts (VanHandel and Song 2010).
In linguistics, the nPVI has been used to delineate quantitative differences between stress and syllable timed languages. Recently in the past decade, music science researchers have used the nPVI to attempt to investigate claims about the relationship between speech and music (Daniele and Patel 2004; Patel and Daniele 2003; VanHandel and Song 2010). While results are mixed regarding the nPVI’s predictive ability and there have been recent calls to limit the measure’s use (Condit-Schultz 2019), it does serve as a very good example of a computational derived measure. Just like summarizing the range of a melody by subtracting the distance between the lowest and highest notes, the nPVI summarizes a phrase and importantly assumes that this measure is representative of the entire phrase the calculation was performed upon.
In computational musicology, features of melodies can generally be classified into two main types: static and dynamic features. Static features compute a summary measure over the entire melody while dynamic features calculate values for each event onset in a melody. One of the most complete set of static computational measures as applied to music perception come from Daniel Müllensiefen’s’ Feature ANalysis Technology Accessing STatistics (In a Corpus) or FANTASTIC toolbox (Mullensiefen 2009). According to FANTASTIC’s technical report,
“FANTASTIC is a program…that analyzes melodies by computing features. The aim is to characterise a melody or a melodic phrase by a set of numerical or categorical values reflecting different aspects of musical structure. This feature representation of melodies can then be applied in Music Information Retrieval algorithms or computational models of melody cognition.” (pp. 4)
Drawing from fields both central and peripheral to music science, FANTASTIC computes a collection of 38 features to analyze features of melodies and joined a large and continuing tradition of analyzing music computationally (Lomax 1977 , 1977; Eerola, Louhivuori, and Lebaka 2009; Huron 1994; Lartillot and Toiviainen 2007; McFee et al. 2015; Steinbeck 1982). Additionally, FANTASATIC also provides a framework for comparing the features of a melody with a parent corpus from which the melody is assumed to belong similar to a sample-population relationship.
4.3.2 Back to the Classroom
Returning to the Aural Skills classroom, many of these features can be used to approximate the previously established intuitions of complexity as agreed upon by theorists. Below in Figure 4.27, I plot the the mean difficulty and grammar ratings given by experts for each melody in the experimental sample against each of the output of FANTASTIC’s features by correlating the two measures. Additionally, ?? displays the five strongest positive and negatively correlated features of FANTASTIC’s output with the ground truth, expert ratings.
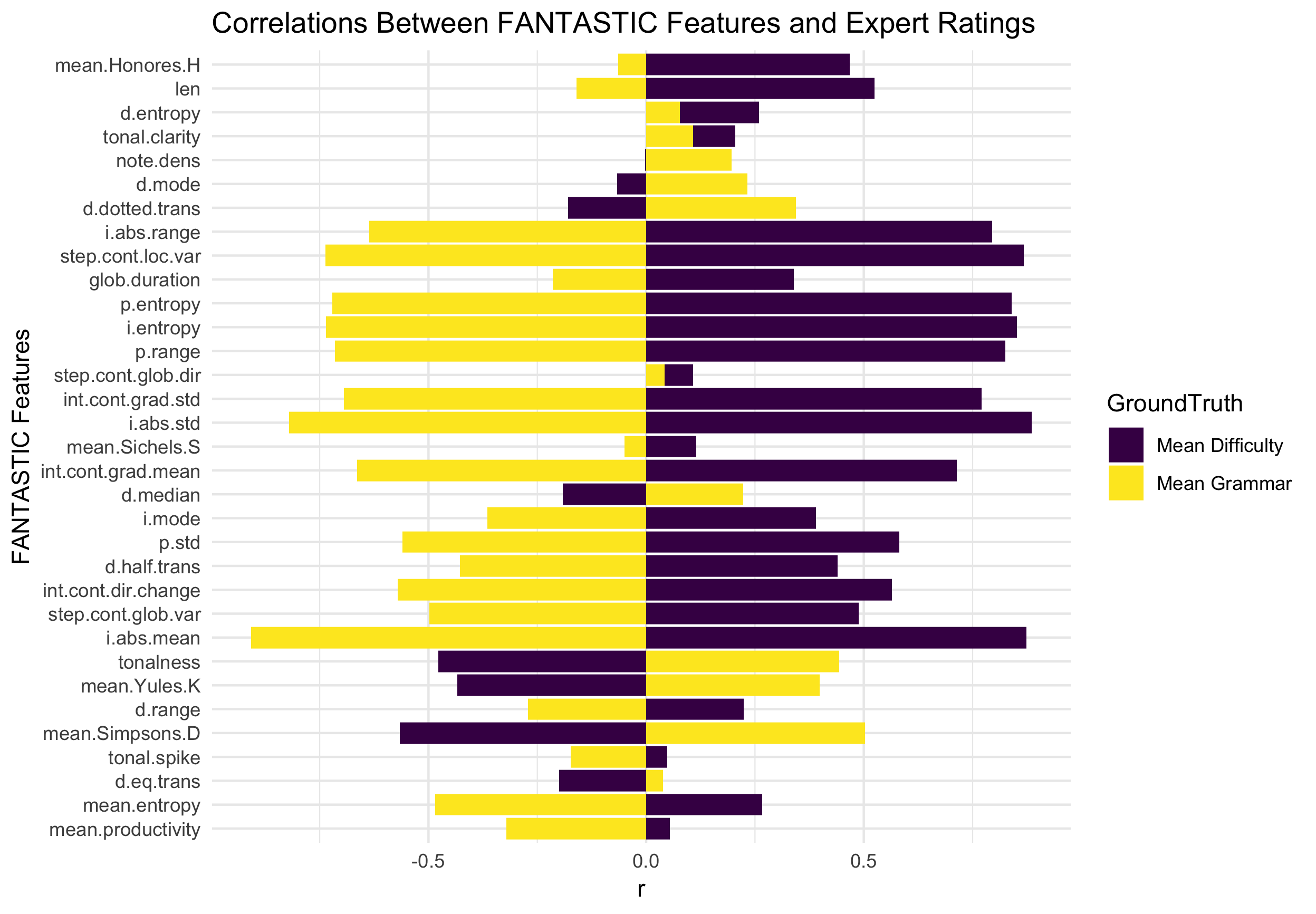
Figure 4.27: FANTASTIC and Expert Ratings
| Feature | Difficulty | Grammar |
|---|---|---|
| i.abs.std | 0.89 | -0.82 |
| i.abs.mean | 0.87 | -0.91 |
| step.cont.loc.var | 0.87 | -0.74 |
| i.entropy | 0.85 | -0.74 |
| p.entropy | 0.84 | -0.72 |
| d.median | -0.19 | 0.22 |
| d.eq.trans | -0.20 | 0.04 |
| mean.Yules.K | -0.43 | 0.40 |
| tonalness | -0.48 | 0.44 |
| mean.Simpsons.D | -0.57 | 0.50 |
From Figure 4.27 and Table ??, there are some features that share a strong relationship with the ground truth of the expert intuitions.
The top five features that correlate most strongly with the expert ground truths are related to the intervallic content of a melody.
The first two features, i.abs.std and i.abs.mean are derived measures using absolute interval distance computations.
The other top three features, step.cont.loc.var, i.entropy, and p.entroy are related to entropy measures.
Of the negatively correlated features, two linguistically derived measures mean.Yules.K and mean.Simpsons.D both correlate with perceived difficulty, as does a measure of tonalnesss which in FANTASTIC is based on the Krumhansl key profiles (Krumhansl 2001).
One problem in tackling this problem is that although many of these variables correlate strongly with our target variables– both grammar and difficulty ratings– one aspect not apparent in this analysis is the correlation between each of the features. In order to demonstrate this, in Figure 4.28 I visualize how a sample of features from the FANTASTIC toolbox correlate with one another with mode additionally included to highlight the breakdown of the corpus.
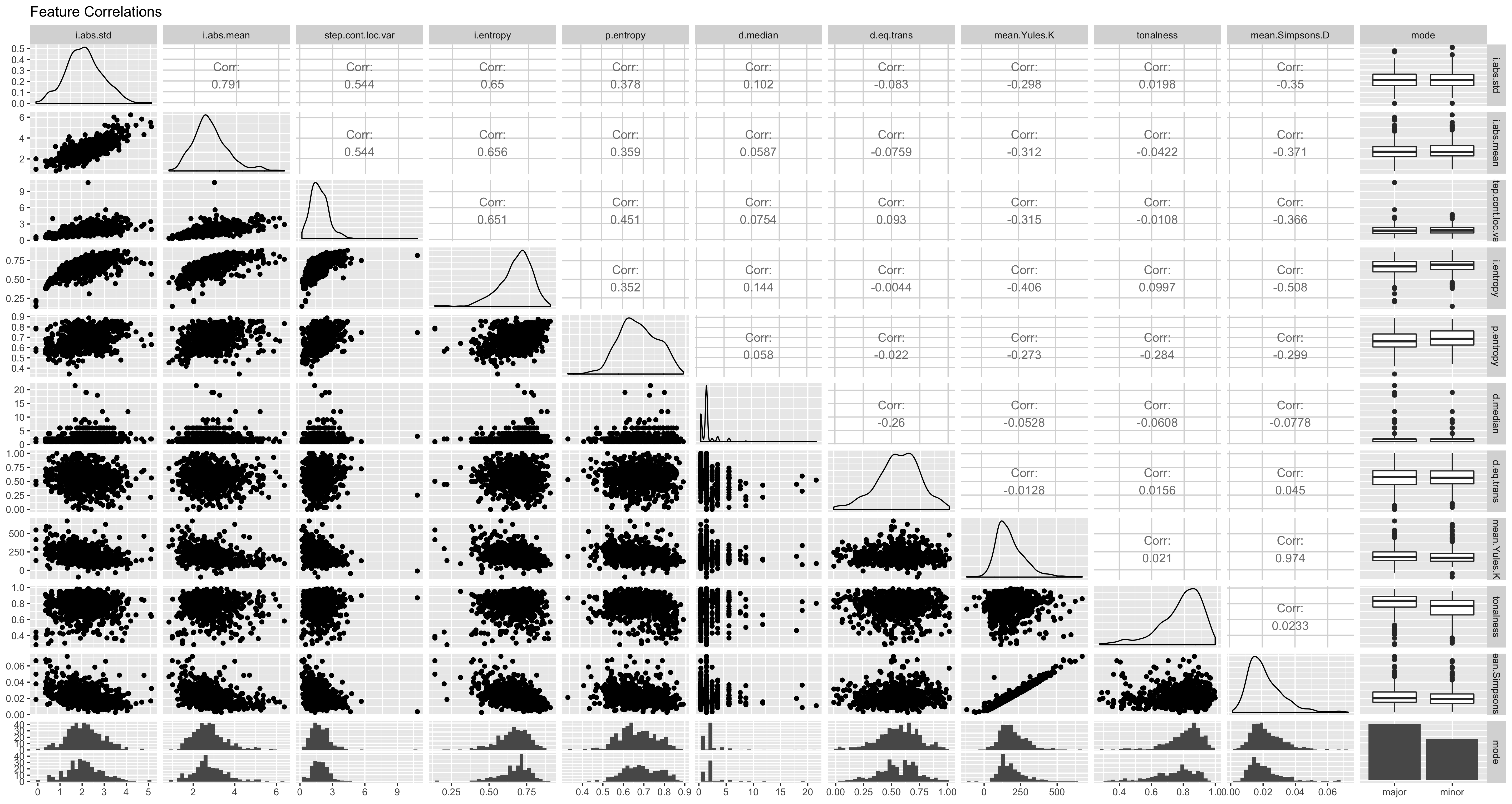
Figure 4.28: Problems of Melodic Collinearity
Among these variables, we see that there is a very high degree of correlation between many of the variables.
For example, the two features inspired from linguistics– mean.Yules.K and mean.Simpsons.D – exhibit an alarming degree of correlation.
We also see in this dataset evidence of the inappropriateness of including some variables such as d.median, a measure relating rhythm.
Here in 4.28 we see computational evidence of claims made by Taylor and Pembrook (1983) when reviewing exactly what features might contribute to the degree of difficulty from a melodic dictation. Given this collinearlity problem, it becomes very difficult to be able to isolate the effect of one feature of the melody. One way to begin to understand these relationships would be to be to build statistical models that are able to partition covariance structures such as the general linear model when used in the context of multiple regression. Another method, as mentioned above, could instead take a more exhaustive, but less explanatory approach forward and follow past research (Baker and Müllensiefen 2017; Harrison, Musil, and Müllensiefen 2016), that uses data reductive techniques such as principal components analysis to obtain more accurate predictive measures of complexity.
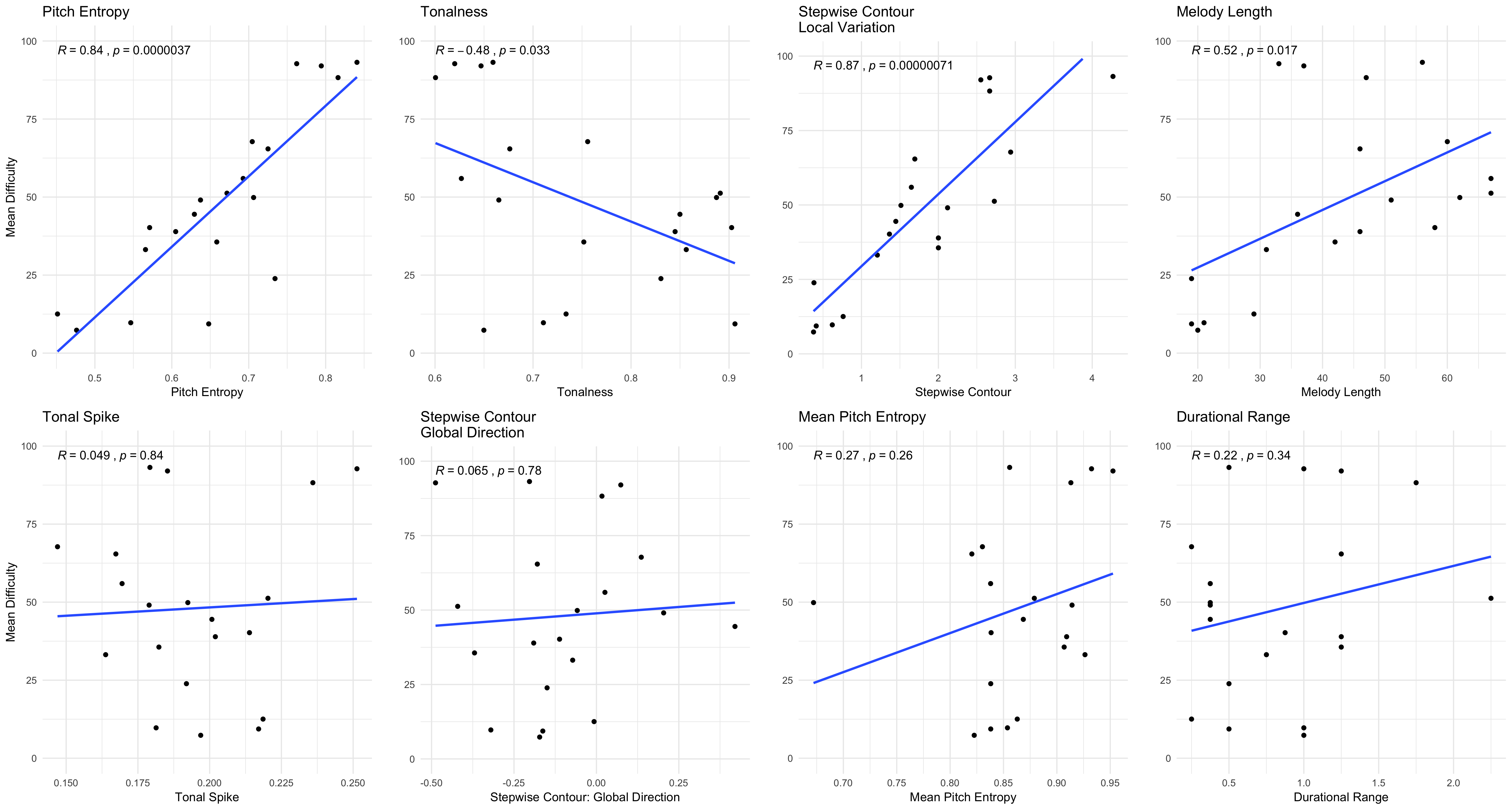
Figure 4.29: Univariate Feature Models
In Figure 4.29, I plot eight features extracted via the FANASTIC Toolbox.
The figure plots linear models of each feature compared against the expert ratings of difficuty.
I additionally list the Pearson correlation coeffecient for each model.
From the plot, it is evident that some features correlate much stronger with the ground truth features than others.
For example, pitch.entropy correlates with the ground truth data \(r = .84\).
Not only that, but the model is not being driven completely by outliers.
While some points fall below the regression line, extreme values are not driving this effect.
A similarly strong relatioship is evident with the step.cont.local.var variable.
In line with work by Dowling, this provides further evidence that countour changes have a significant impact on how people hear melodies (Dowling 1978).
In exploring these relationships in multivariate context, when I combined the top four variables from 4.29 in a linear multiple regression model, the model was able to predict a high degree of variance \(F(4,15) = 30.47, p < .05, R^2 = .89\).
While this model is explicitly exploratory, this dataset will serve as a foundation to build future theories to test.
Relating back to its implication for aural skills pedagogy, the above analysis suggests that features derived from the FANTASTIC toolbox can provide a meaningful step forward in helping standardize the assessment of aural skills pedagogy. If pedagogues were able to employ tools such as the FANTASTIC toolbox, pedagogues could not only select melodies for their own work that are able to hold certain features constant, but the use of this research could also be used to generate melodies based on the desired difficulty parameter measures in order to design course curricula that would foster a more stable curricular path among students. Additionally, students could also work at slowly challenging themselves if this were to be incorporated into an online pedagogical learning application or website.
Although this approach has been relatively successful at modeling expert ratings, using FANTASTIC’s various linear combinations of these features does have important limitations. One of the most obvious limitations is that FANTASTIC’s measures tacitly assume listeners recall melodies in some sort of perceptual suspended animation. Illuminating this problem using a more tangible example, again returning to melodies 4.1 and 4.2, when the full set of FANTASTIC features are computed on both, the both melodies are computational equivalent in their range, pitch entropy, durtational range, durational entropy, length, tonalness, tonal clarity, tonal spike and stepwise contour global variation. This computation arises from computing a summary measure over the melody and not modeling it in terms of real time perception. In order to have a more phenomenologically appropriate model that incorporates computationally derived features, it is important to also consider dynamic models of music perception when modeling difficulty. Following up on another finding from this section, it also is worthy of mention that the variables with the strongest predictive powers tend to be those associated with information content. In the next section, I explore how using a dynamic approach such as Marcus Pearce’s implementation (Pearce 2005, 2018) of a multiple viewpoints model (Conklin and Witten 1995), might provide more insights into understanding the aural skills classroom.
4.3.3 Dynamic
The Information Dynamic of Music (IDyOM) model of Marcus Pearce is a computational model of auditory cognition (Pearce 2018). IDyOM is based on the assumption put forward by Leonard Meyer that musical style can be understood as a complex network of probabilistic relationships that underlie a musical style and is implicitly understood by a musical community (Pearce and Wiggins 2012; Pearce 2005, 2018) that incorporates a multiple viewpoint framework (Conklin and Witten 1995). Unlike measures from FANTASTIC, which calculate summary statistics based on melodic features, IDyOM works by calculating measures of expectancy of an event based on a predefined set of musical parameters that the model was trained on. As mentioned in Chapter 2, the IDyOM model relies on two important theoretical assumptions based on two neural mechanisms involved in musical enculturation: the statistical learning hypothesis and probabilistic prediction hypothesis. According to Pearce, the Statistical Learning Hypothesis (SLH) states that:
musical enculturation is a process of implicit statistical learning in which listeners progressively acquire internal models of the statistical and structural regularities present in the musical styles to which they are exposed, over short (e.g., an individual piece of music) and long time scales (e.g., an entire lifetime of listening). p.2 (Pearce, 2018)
The logic here is that the more an individual is exposed to a musical style, the more they will implicitly understand its internal syntax and rules. The SLH leads the corroborating probabilistic prediction hypothesis which Pearce states as:
while listening to new music, an enculturated listener applies models learned via the SLH to generate probabilistic predictions that enable them to organize and process their mental representations of the music and generate culturally appropriate responses. p.2 (Pearce, 2018).
IDyOM works by providing the model with a musical corpus that it assumes is representative of a genre or musical style. This musical corpus then serves as training data to approximate either a listener’s ground truth or musical style. After establishing this corpus, IDyOM then learns both long term and short term expectations of events using a variable-order Markov model in order to best optimize its predictive abilities in line with theoretical frameworks provided by Conklin and Witten (1995). The expectations that IDyOM calculates are based on a probability distribution of the proceeding events, which is then quantified in terms of information content (Shannon 1948). As detailed in a summary review article on IDyOM by Pearce, IDyOM has been successful at predicting
Western listeners’ melodic pitch expectations in behavioral, physiological, and electroencephalography (EEG) studies using a range of experimental designs, including the probe-tone paradigm visually guided probe-tone paradigm a gambling paradigm, continuous expectedness ratings, and an implicit reaction-time task to judgments of timbral change.
Peace notes some of IDyOM successes in modeling beyond expectation, including successes in modeling emotional experiences in music, recognition memory, perceptual similarity, phrase boundary perception and metrical inference. Importantly in reviewing IDyOM’s capabilities regarding memory for musical pitches, Pearce also claims that
A sequence with low IC is predictable and thus does not need to be encoded in full, since the predictable portion can be reconstructed with an appropriate predictive model; the sequence is compressible and can be stored efficiently. Conversely, an unpredictable sequence with high IC is less compressible and requires more memory for storage. Therefore, there are theoretical grounds for using IDyOM as a model of musical memory.
Peace notes four studies (Bartlett and Dowling 1980; Cohen, Cuddy, and Mewhort 1977; Cuddy and Lyons 1981; Halpern, Bartlett, and Dowling 1995) that show that more complex melodies are more difficult to hold in memory. This theoretical assertion and select empirical findings have important ramifications for the aural skills classroom. In a dictation setting, melodies that are more expected should tax memory less, thus making them easier to remember and dictate. If I assume that more expected melodies are easier to remember, then it follows that the information content measures of expectedness can then be used as a stand in measure of melodic memory. This notion is not new to music psychology and was discussed by David Huron relating exposure to musical material as following similar laws to the the Hick-Hyman hypothesis (Hick 1952; Hyman 1953), which Huron paraphrases as “processing of familiar stimuli is faster than processing of unfamiliar stimuli” (Huron 2006, 63)". Now a decade later, this assertion can be further investigated using tools from computational musicology. Combining the Hick-Hyman hypothesis together with the above statistical learning hypothesis and probabilistic prediction hypothesis, I then put forward a new hypothesis: the frequency facilitation hypothesis.
4.4 Frequency Facilitation Hypothesis
The frequency facilitation hypothesis (FFH) makes two important assumptions that rely on both the statistical learning hypothesis and the perceptual facilitation hypothesis. The first, as stated above, is that humans learn melodies via the statistical learning hypothesis. In line with Huron’s reading of the Hick-Hyman Law, melodic information that listeners are more familiar with will consequently be processed more quickly. More expected notes will tax memory processing less than unexpected notes. This assertion would also be predicted by the probabilistic prediction hypothesis. Thus, given a sequence any set of notes, the frequency facilitation hypothesis posits that the efficiency in which a melody is processed in memory is proportionally related to its degree of expectedness when quantified in information content. Specifically, measures of expectation derived from computational models of auditory cognition like IDyOM should be able to serve as a proxy for musical information. This falls within the bounds of Pearce’s assertion that using the expectancy measures from a melody could be used as a sort of memory proxy (Pearce 2018).
This hypothesis generates testable predictions that can be investigated to verify its verisimilitude. Important to aural skills pedagogy, the primary prediction from this hypothesis would be that melodic patterns that occur more frequently in a corpus will be be easier to remember than those occurring less frequently. These frequency patterns should then directly relate to the amount of information content calculated by IDyOM. If this relationship does exist, then it can be used to develop strategies that would then create a more linear path to success for students learning to take melodic dictation. In the final section of this chapter, I investigate this claim by conducting an analysis on a corpus of sight singing melodies to demonstrate this claim. I then take the findings from this corpus analysis and how it can be applied in the aural skills classroom.
4.4.1 Corpus Analysis
In order to investigate the frequency facilitation hypothesis, I conducted a corpus study using N = 622 melodies from the above using the Fifth Edition of the Berkowitz “A New Approach to Sight Singing” (Berkowitz 2011). The FFH predicts that more frequently occurring patterns will result in lower information content– a general by-product of quantifying musical feature tokens with information content in a multiple viewpoints framework– and that these lower information content measures, when quantified, will be able to predict load on memory.
In order to examine this, I first extracted a series of the most frequently occurring melodic tri-grams from a subset of the MeloSol corpus after transposing each melody to C major via the solfa tool in humdrum.
I plot the resulting distributions of the top 1,000 patterns of each fixed order predictions below in 4.30 and 4.31.
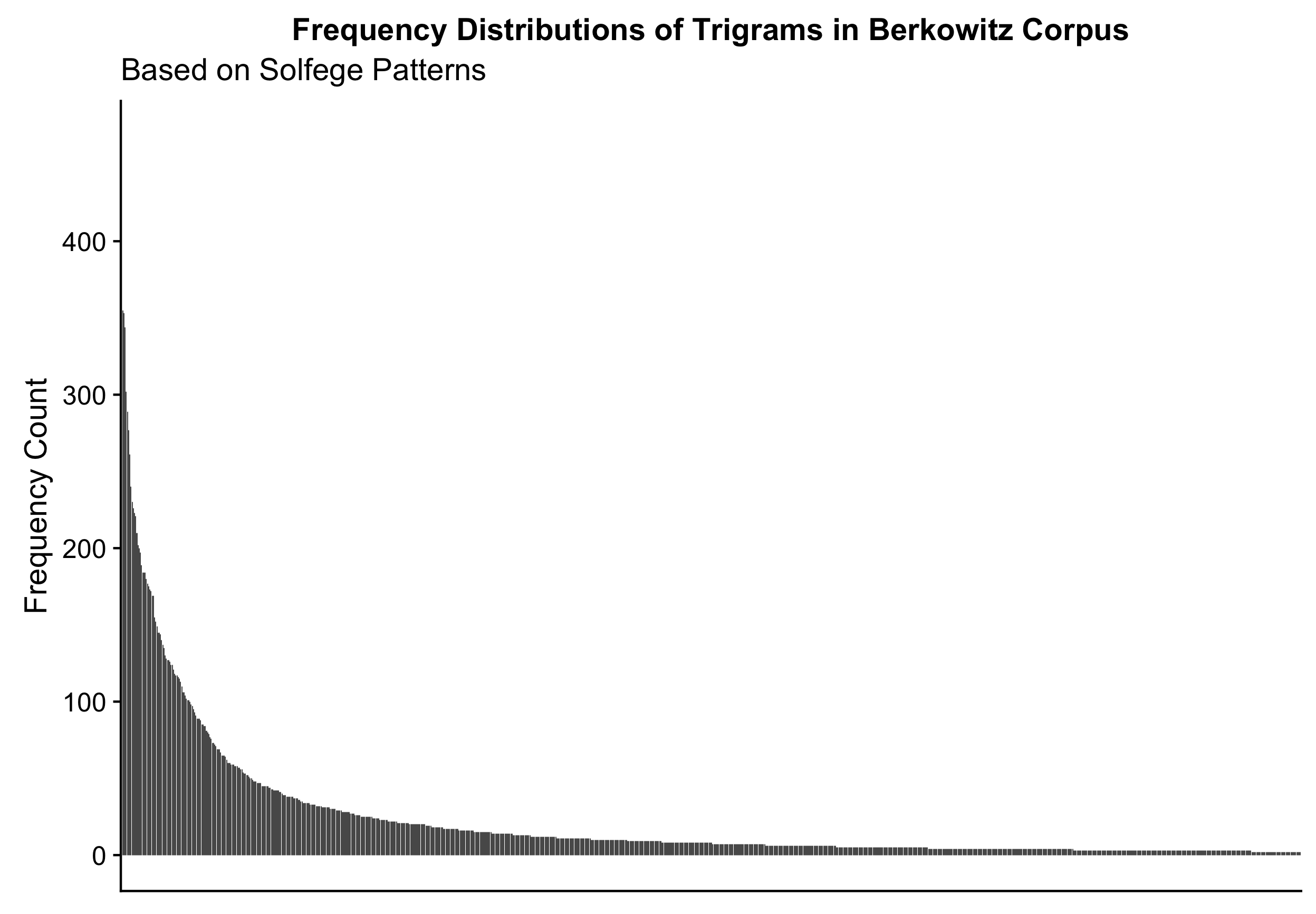
Figure 4.30: Distribution of m-grams
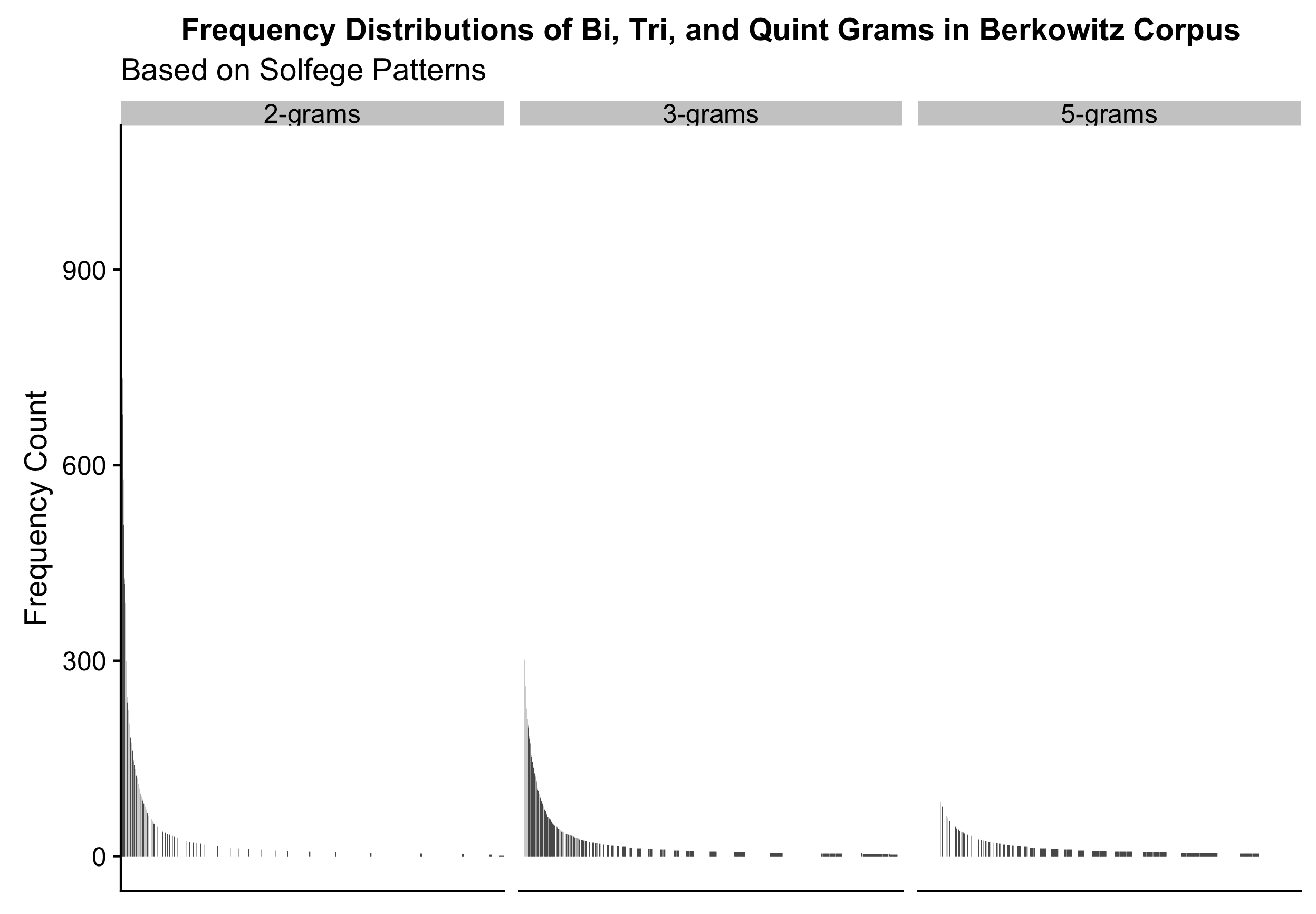
Figure 4.31: Less Predictive Power
From 4.30, we see that when plotted in terms of their frequency distributions, a small amount of the patterns make up for a very large the distribution of the corpus. As evident from 4.30, we see that with the addition of more tokens added to the n-grams, this results in a visual representation of why and how statistical predictions become more unreliable with higher order predictions (Conklin and Witten 1995). Intuitively, melodic patterns from the high frequency distribution of the table would seemingly be easier to remember and then dictate than those from the tails of the distributions.
Following up on this analysis, I then trained an IDyOM model on the same corpus of melodies and was able to calculate the average information content for the first five notes of each melody in the corpus. In this computation, I explicitly assume that the underlying corpus of data is representative of an individual’s personal expectations of musical material. In Figure 4.32, I visualize the cumulative information content of the first five notes of each of melodies that the corpus was trained on. I chose to additionally split the corpus into quintiles to further highlight the progressive changes in information content when these incipits are sorted based on their cumulative information content.
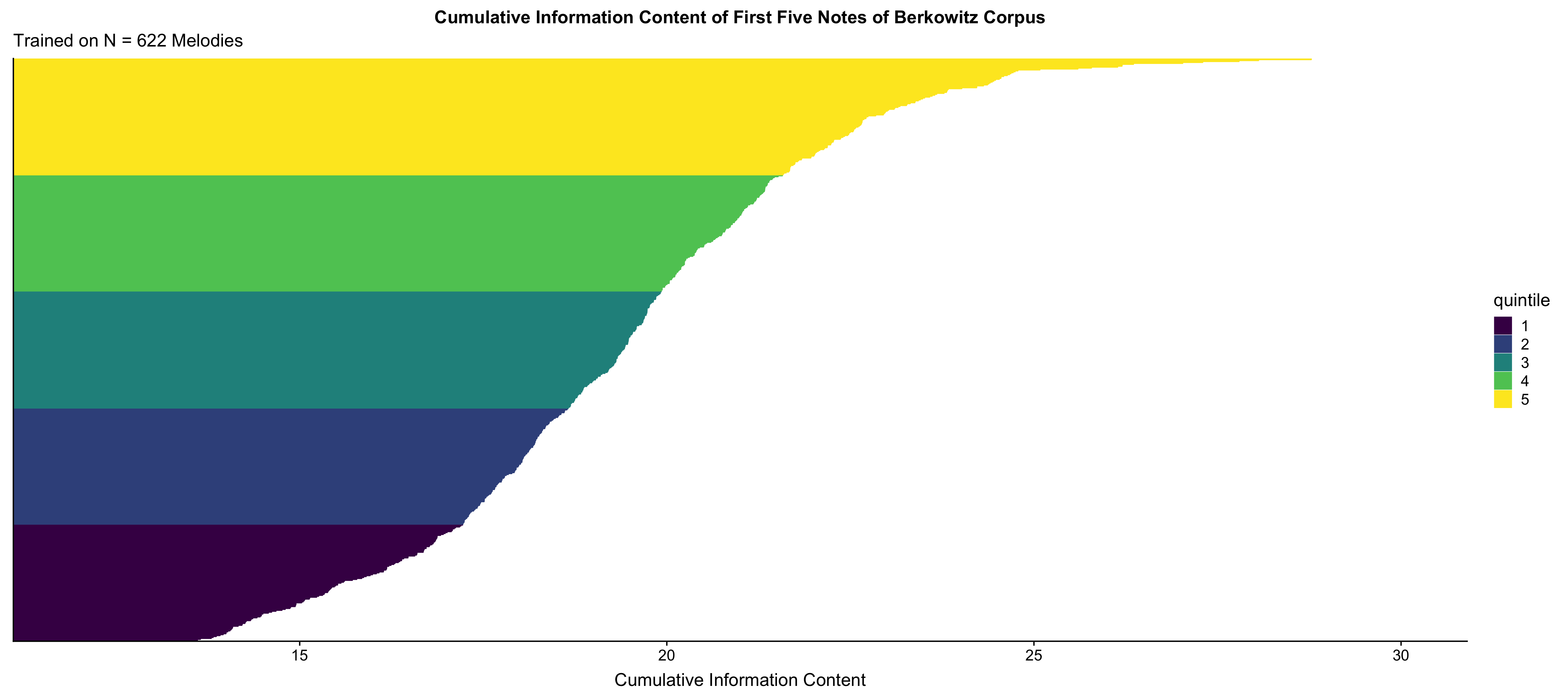
Figure 4.32: Distribution of Opening Five Grams
This observation may seem tautological, as this relationship would result from how information content is calculated since more expected patterns have less information content. The novel assertion here is connecting the cumulative information content to memory load. For example, in Figure 4.33, we see that when split into three sections, even just the opening of the first five notes of each melody increase per group.
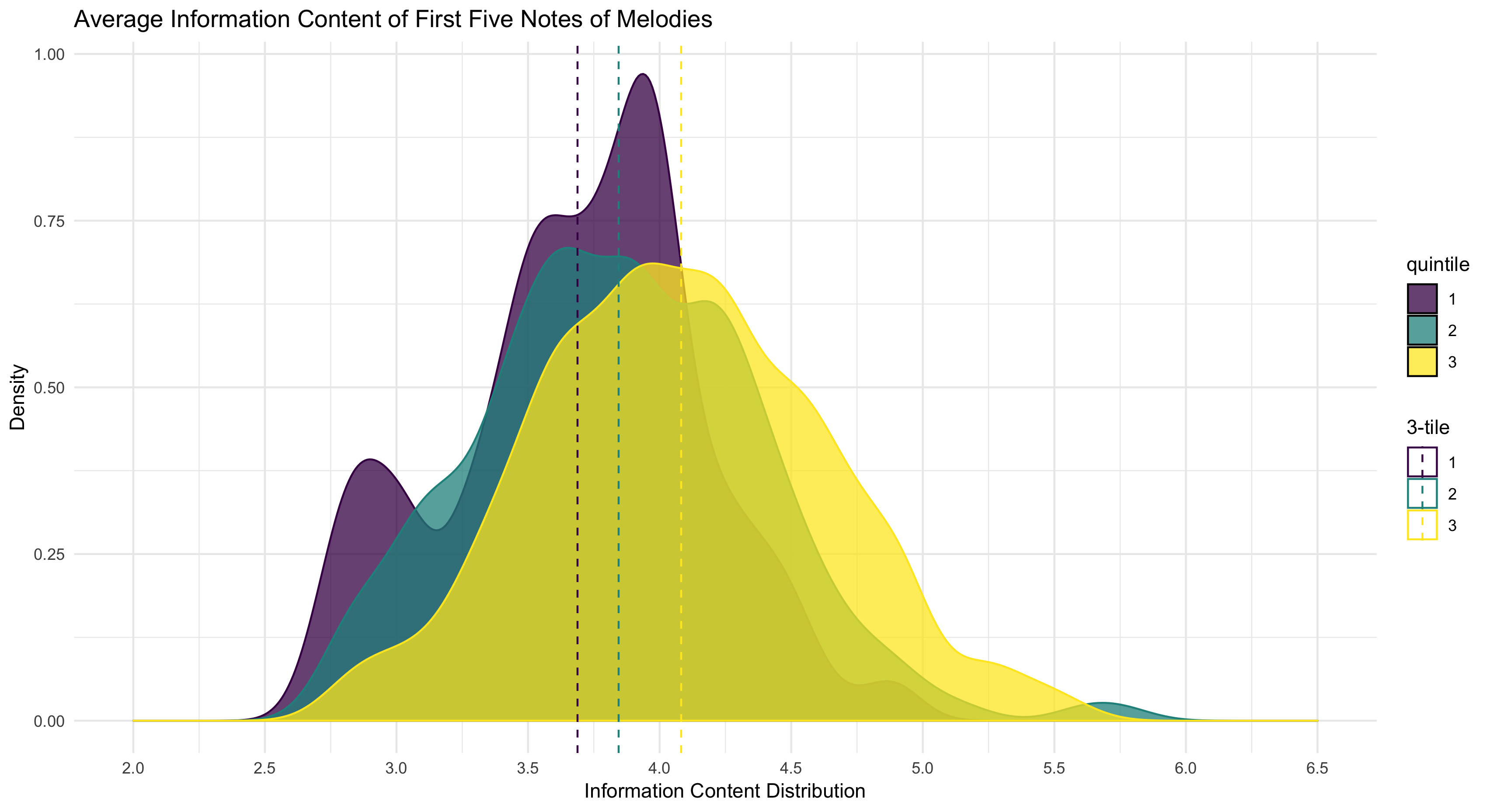
Figure 4.33: Average Information Content of First Five Notes of Melodies
To visualize what this might look like in a melodic dictation context, we could imagine randomly sampling melodies from even smaller sections. If quantified using information content measures, these five grams would then fill up the finite bin of memory faster than five grams that were more unexpected, or had more information content associated with them. I visualize this difference in Figure 4.34 where I plot similar lengths of five grams filling up the window of memory at different rates based on their cumulative information content.
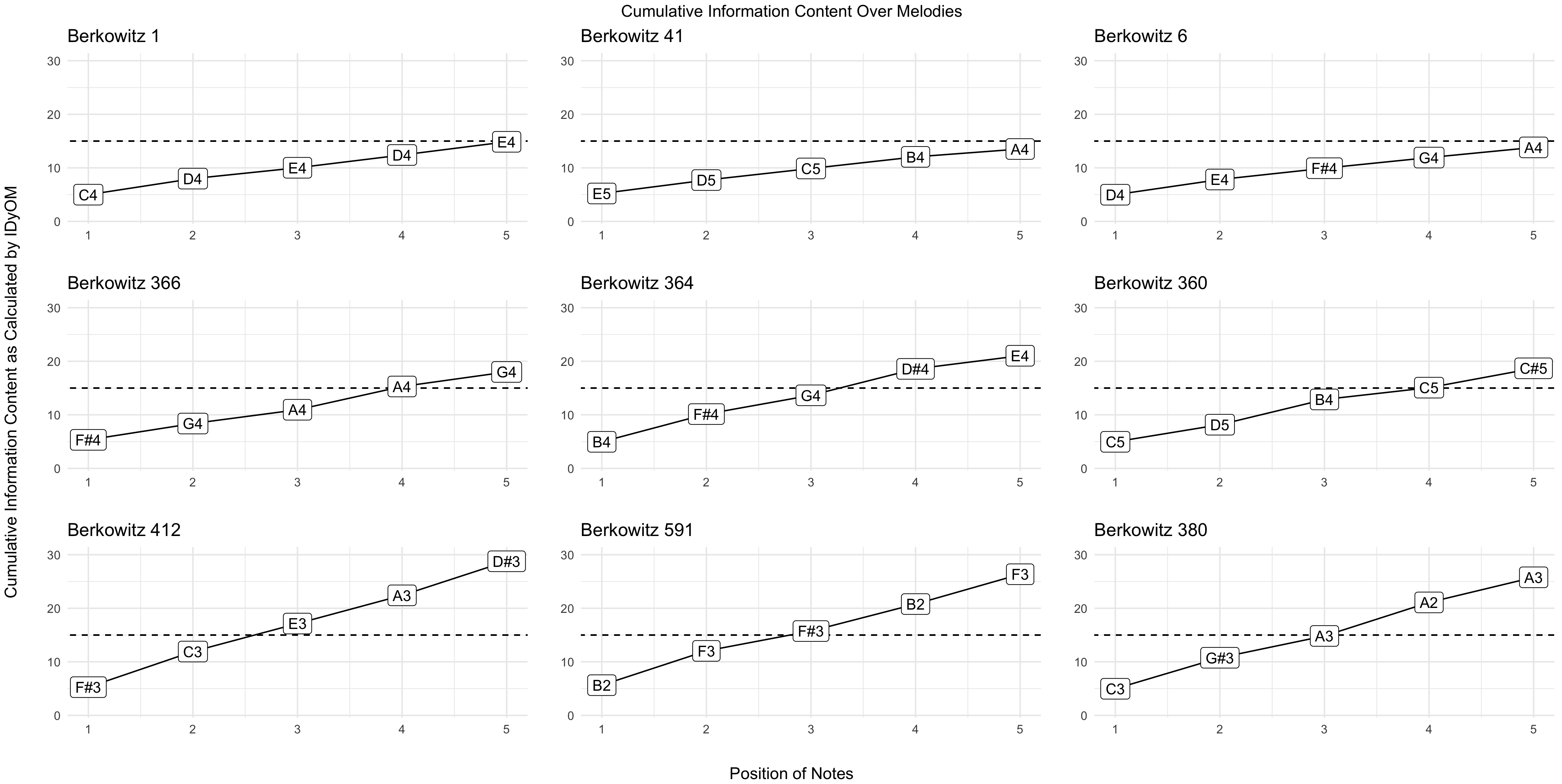
Figure 4.34: Cumlative Information Content in Melodic Incipts
Lastly, to further investigate this claim of cumulative information content, I calculated various information content measures for each melody used the survey above then using the resulting data to plot it against the measures of expert ratings of difficulty for the classroom. In Figure ??, the resulting visualization shows measures of information content to be very good predictors of difficulty ratings. I believe that this gives credence to thinking more about using computational measures in designing appropriate curricular measures.
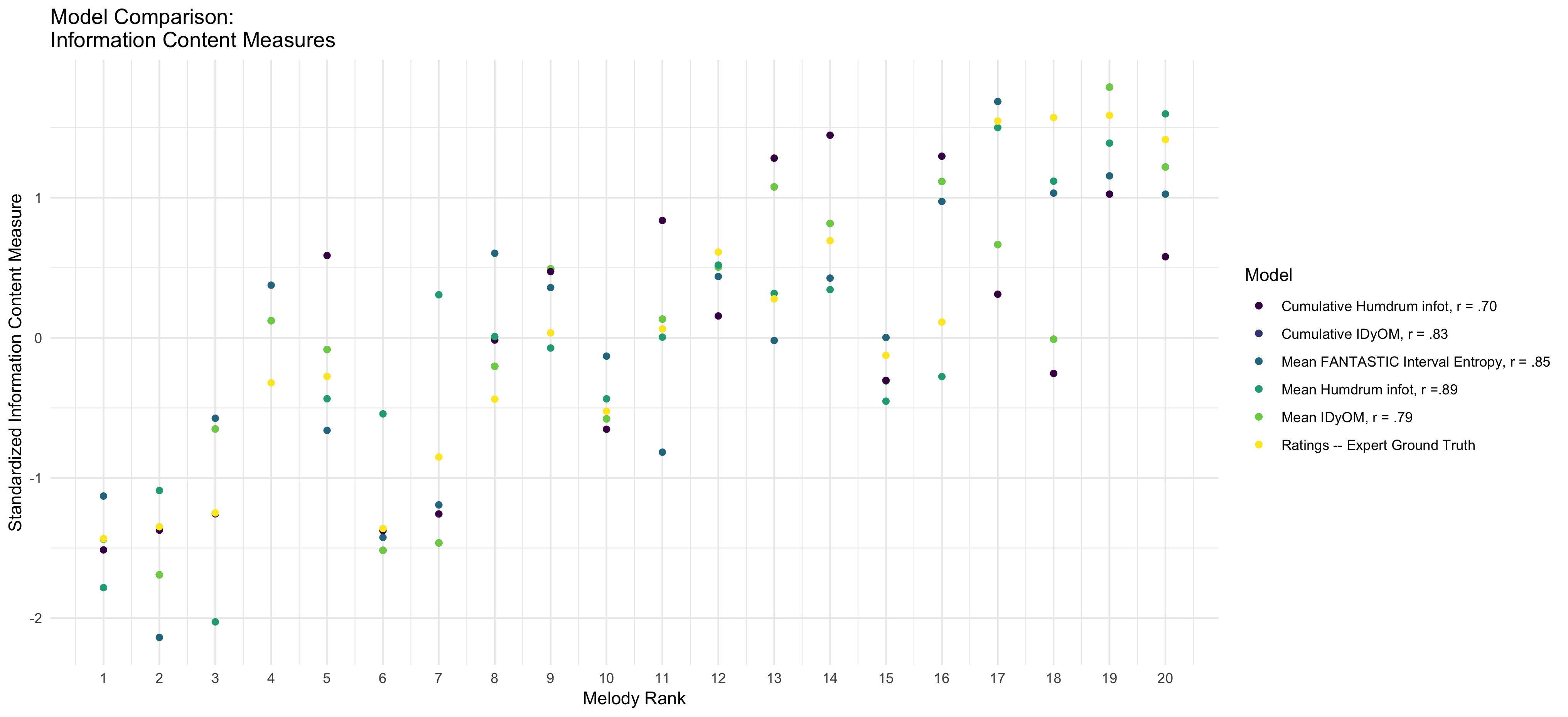
Figure 4.35: Model Comparison
4.4.2 Implications
If true, the frequency facilitation hypothesis would have direct implications for the aural skills classroom, specifically for melodic dictation. If measures of information content could be used as a more reliable proxy for load on memory, then a more linear path to learning patterns could result in better strategies for learning to take dictation. For example, the first practical application of this could be that information content could be a more accurate proxy for the limits of musical memory as opposed to using older measures asserted by the literature that follow in the George Miller 7 \(\pm\) 2 tradition, which attempts to logically substitute items in memory for musical notes. As discussed in Working Memory and Melodic Dictation, using measures of information content could provide an ecologically acceptable solution to the problems of chunking within music. For example, if this measure proved to be useful in pedagogical applications, pedagogues would have a very powerful tool to create curricula that was designed in a much more linear path to help students learn.
One of the major challenges in both teaching and learning aural skills beyond the identification of scale degrees is identifying them in a more ecological, melodic context. Presenting incipits of melodies could be then used as a very small intermediate step in teaching melodic dictation where students can experience more frequent successes in the aural skills classroom while trying to dictate progressively difficulty snippets. If they learn the more frequent n-grams first, they will find them easier, but more importantly will begin to recognize these patterns in longer exercises.
Instead of picking melodies for practice one-by-one, pedagogues could instead give students a large compendium of small dictation exercises that were ordered to increase in their melodic information content over the course of instruction. In this type of application, students would not be learning to increase their melodic information capacity limit per se, but could provide a valuable means to give students multiple, smaller attempts to learn to take dictation, rather than being overwhelmed with longer melodies that are given to study on the premise of more ecological validity. This could be done from the level of scale degree identification to that of full melodies. Future work should investigate this experimentally and look to model it using similar methodologies that have been employed in music psychology testing paradigms (Harrison, Collins, and Müllensiefen 2017; Wolf and Kopiez 2014). Finally, if useful, this type of modeling could also be used in future computational models of melodic dictation as explored in the final chapter of this dissertation.
4.4.3 Limitations of Frequency Facilitation Hypothesis
This conceptualization of calculating the information content of melodies is not without its limitations. One of the core assumptions to this approach is that statistical learning does in fact take place. While this assumption is ubiquitous in much of the music psychology literature, statistical learning as a concept has been critiqued in other related fields and deserves mentioning. Statistical learning rests on the premise that organisms are able to implicitly learn and track the statistical regularities in their environments. In the case of auditory learning, there is research to assert this claim from both the field of implicit learning and statistical learning as discussed by Perruchet and Pacton (2006). For example, extensive evidence as reviewed by Cleeremans and Dienes (2008) provides many examples of this, and especially worth highlighting is that people have been show to learn variable order n-gram patterns (Remillard and Clark 2001).
This assertion is importantly contrasted by work such as Jamieson and Mewhort (2009) who claim that explaining these phenomena as resulting in statistical learning is not necessary. Rather, Jamieson and Mewhort (2009) assert that employing memory models like that of Minerva 2 can accurately model behavioral patterns in individual responses without the theoretical framework of statistical learning. They instead note that similar results can be obtained from individuals making similarity judgments. This assertion is important to highlight because as noted by Perruchet and Pacton (2006), statistical learning depends on the tacit assumption that people might be performing some sort of real-time calculations on incoming stimuli in real time. Another important caveat in the corpus analysis above is it was done using fixed order search patterns, whereas the calculations from IDyOM are based on variable order Markov-Models.
4.5 Conclusions
In this chapter, I demonstrated how tools from computational musicology can be used as an aide in aural skills pedagogy. After first establishing the extent to which aural skills pedagogues agree on various melody parameters, I then show how two types of computationally derived features can stand in for a pedagogues intuition. First, using the FANTASTIC toolbox, I show how static abstracted features can help explain how theorists conceceptualize complexity. This first will help with selection of melodies and also provides insights as to which features of the melodies contribute most to perceived difficulty. Second, I demonstrated how assumptions derived from the IDyOM framework can serve as a basis for the intuitions of why smaller sequences of notes within melodies are more or less difficult to dictate. Using the logic that sequences that are easier to process are more expected and thus could plausbibly tax memory less than are more difficult to process. I relate this to the classrom by asserting that students could then take a melodic incipt approach to learning to dictate. I argued that using this smaller incipit based approach will allow students to not be overwhelmed in their learning by taking a more linear path to dictation, before moving on to more more ecologically valid melodies.
References
Ottman, Robert W., and Nancy Rogers. 2014. Music for Sight Singing. 9th ed. Upper Saddle River, NJ: Pearson.
Berkowitz, Sol, ed. 2011. A New Approach to Sight Singing. 5th ed. New York: W.W. Norton.
Karpinski, Gary S. 2007. Manual for Ear Training and Sight Singing. New York: Norton.
Cleland, Kent D., and Mary Dobrea-Grindahl. 2010. Developing Musicianship Through Aural Skills: A Holisitic Approach to Sight Singing and Ear Training. New York: Routledge.
Cambouropoulos, Emilios. 2009. “How Similar Is Similar?” Musicae Scientiae 13 (1_suppl): 7–24. https://doi.org/10.1177/102986490901300102.
Kahneman, Daniel. 2012. Thinking, Fast and Slow. London: Penguin Books.
Logg, Jennifer M., Julia A. Minson, and Don A. Moore. 2019. “Algorithm Appreciation: People Prefer Algorithmic to Human Judgment.” Organizational Behavior and Human Decision Processes 151 (March): 90–103. https://doi.org/10.1016/j.obhdp.2018.12.005.
Meehl, Paul E. 1954. Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence. Minneapolis: University of Minnesota Press. https://doi.org/10.1037/11281-000.
Paney, Andrew S., and Nathan O. Buonviri. 2014. “Teaching Melodic Dictation in Advanced Placement Music Theory.” Journal of Research in Music Education 61 (4): 396–414. https://doi.org/10.1177/0022429413508411.
Koo, Terry K., and Mae Y. Li. 2016. “A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research.” Journal of Chiropractic Medicine 15 (2): 155–63. https://doi.org/10.1016/j.jcm.2016.02.012.
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. “Fitting Linear Mixed-Effects Models Using Lme4.” Journal of Statistical Software 67 (1). https://doi.org/10.18637/jss.v067.i01.
Ortmann, Otto. 1933. “Some Tonal Determinants of Melodic Memory.” Journal of Educational Psychology 24 (6): 454–67. https://doi.org/10.1037/h0075218.
Taylor, Jack A., and Randall G. Pembrook. 1983. “Strategies in Memory for Short Melodies: An Extension of Otto Ortmann’s 1933 Study.” Psychomusicology: A Journal of Research in Music Cognition 3 (1): 16–35. https://doi.org/10.1037/h0094258.
Pembrook, Randall G. 1986. “Interference of the Transcription Process and Other Selected Variables on Perception and Memory During Melodic Dictation.” Journal of Research in Music Education 34 (4): 238. https://doi.org/10.2307/3345259.
Akiva-Kabiri, Lilach, Tomaso Vecchi, Roni Granot, Demis Basso, and Daniele Schön. 2009. “Memory for Tonal Pitches: A Music-Length Effect Hypothesis.” Annals of the New York Academy of Sciences 1169 (1): 266–69. https://doi.org/10.1111/j.1749-6632.2009.04787.x.
Dewitt, Lucinda A., and Robert G. Crowder. 1986. “Recognition of Novel Melodies After Brief Delays.” Music Perception: An Interdisciplinary Journal 3 (3): 259–74. https://doi.org/10.2307/40285336.
Eerola, Tuomas, Jukka Louhivuori, and Edward Lebaka. 2009. “Expectancy in Sami Yoiks Revisited: The Role of Data-Driven and Schema-Driven Knowledge in the Formation of Melodic Expectations.” Musicae Scientiae 13 (2): 231–72. https://doi.org/10.1177/102986490901300203.
Schulze, Katrin, and Stefan Koelsch. 2012. “Working Memory for Speech and Music: Schulze & Koelsch.” Annals of the New York Academy of Sciences 1252 (1): 229–36. https://doi.org/10.1111/j.1749-6632.2012.06447.x.
Harrison, Peter M.C., Jason Jiří Musil, and Daniel Müllensiefen. 2016. “Modelling Melodic Discrimination Tests: Descriptive and Explanatory Approaches.” Journal of New Music Research 45 (3): 265–80. https://doi.org/10.1080/09298215.2016.1197953.
Mullensiefen, Daniel. 2009. “Fantastic: Feature ANalysis Technology Accessing STatistics (in a Corpus): Technical Report V1.5.”
Baker, David J., and Daniel Müllensiefen. 2017. “Perception of Leitmotives in Richard Wagner’s Der Ring Des Nibelungen.” Frontiers in Psychology 8 (May). https://doi.org/10.3389/fpsyg.2017.00662.
Grabe, Esther. 2002. “Durational Variability in Speech and the Rhythm Class Hypothesis.” Papers in Laboratory Phonology, 16.
VanHandel, Leigh, and Tian Song. 2010. “The Role of Meter in Compositional Style in 19th Century French and German Art Song.” Journal of New Music Research 39 (1): 1–11. https://doi.org/10.1080/09298211003642498.
Daniele, Joseph R, and Aniruddh D Patel. 2004. “THE INTERPLAY OF LINGUISTIC AND HISTORICAL INFLUENCES ON MUSICAL RHYTHM IN DIFFERENT CULTURES,” 5.
Patel, Aniruddh D., and Joseph R. Daniele. 2003. “Stress-Timed Vs. Syllable-Timed Music? A Comment on Huron and Ollen (2003).” Music Perception 21 (2): 273–76. https://doi.org/10.1525/mp.2003.21.2.273.
Condit-Schultz, Nathaniel. 2019. “Deconstructing the nPVI: A Methodological Critique of the Normalized Pairwise Variability Index as Applied to Music.” Music Perception: An Interdisciplinary Journal 36 (3): 300–313. https://doi.org/10.1525/mp.2019.36.3.300.
Lomax, Alan. 1977. Cantometrics: An Approach to the Anthropology of Music: Audiocassettes and a Handbook. Berkle, California: University of California Press.
Huron, David. 1994. “The Humdrum Toolkit: Reference Manual.” Center for Computer Assisted Research in the Humanities.
Lartillot, Olivier, and Petri Toiviainen. 2007. “A Matlab Toolbox for Musical Feature Extraction from Audio.” International Conference on Digigial Audio Effects, 237–44.
McFee, Brian, Colin Raffel, Dawen Liang, Daniel P W Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. 2015. “Librosa: Audio and Music Signal Analysis in Python,” 7.
Steinbeck, W. 1982. Struktur Und Ähnlichkeit: Methoden Automatiserter Melodieanalyse. Kallel: Bärenreiter.
Krumhansl, Carol. 2001. Cognitive Foundations of Musical Pitch. Oxford University Press.
Dowling, W. Jay. 1978. “Scale and Contour: Two Components of a Theory of Memory for Melodies.” Psychological Review 84 (4): 341–54.
Pearce, Marcus. 2005. “The Construction and Evaluation of Statistical Models of Melodic Structure in Music Perception and Composition.” PhD thesis, Department of Computer Science: City University of London.
Pearce, Marcus T. 2018. “Statistical Learning and Probabilistic Prediction in Music Cognition: Mechanisms of Stylistic Enculturation: Enculturation: Statistical Learning and Prediction.” Annals of the New York Academy of Sciences 1423 (1): 378–95. https://doi.org/10.1111/nyas.13654.
Conklin, Darrell, and Ian H. Witten. 1995. “Multiple Viewpoint Systems for Music Prediction.” Journal of New Music Research 24 (1): 51–73. https://doi.org/10.1080/09298219508570672.
Pearce, Marcus T., and Geraint A. Wiggins. 2012. “Auditory Expectation: The Information Dynamics of Music Perception and Cognition.” Topics in Cognitive Science 4 (4): 625–52. https://doi.org/10.1111/j.1756-8765.2012.01214.x.
Shannon, Claude. 1948. “A Mathematical Theory of Communication.” Bell System Technical Journal 27: 379–423.
Bartlett, James C, and W Jay Dowling. 1980. “Recognition of Transposed Melodies: A Key-Distance Effect in Developmental Perspective,” 15.
Cohen, Annabel J., Lola L. Cuddy, and Douglas J. K. Mewhort. 1977. “Recognition of Transposed Tone Sequences.” The Journal of the Acoustical Society of America 61 (S1): S87–S88. https://doi.org/10.1121/1.2015950.
Cuddy, Lola L., and H. I. Lyons. 1981. “Musical Pattern Recognition: A Comparison of Listening to and Studying Tonal Structures and Tonal Ambiguities.” Psychomusicology: A Journal of Research in Music Cognition 1 (2): 15–33. https://doi.org/10.1037/h0094283.
Halpern, Andrea, James Bartlett, and W.Jay Dowling. 1995. “Aging and Experience in the Recognition of Musical Transpositions.” Psychology and Aging 10 (3): 325–42.
Hick, W. E. 1952. “On the Rate of Gain of Information.” Quarterly Journal of Experimental Psychology 4 (1): 11–26. https://doi.org/10.1080/17470215208416600.
Hyman, Ray. 1953. “Stimulus Information as a Determinant of Reaction Time.” Journal of Experimental Psychology 45 (3): 188–96. https://doi.org/10.1037/h0056940.
Huron, David. 2006. Sweet Anticipation. MIT Press.
Harrison, Peter M. C., Tom Collins, and Daniel Müllensiefen. 2017. “Applying Modern Psychometric Techniques to Melodic Discrimination Testing: Item Response Theory, Computerised Adaptive Testing, and Automatic Item Generation.” Scientific Reports 7 (1). https://doi.org/10.1038/s41598-017-03586-z.
Wolf, Anna, and Reinhard Kopiez. 2014. “Do Grades Reflect the Development of Excellence in Music Students? The Prognostic Validity of Entrance Exams at Universities of Music.” Musicae Scientiae 18 (2): 232–48. https://doi.org/10.1177/1029864914530394.
Perruchet, Pierre, and Sebastien Pacton. 2006. “Implicit Learning and Statistical Learning: One Phenomenon, Two Approaches.” Trends in Cognitive Sciences 10 (5): 233–38. https://doi.org/10.1016/j.tics.2006.03.006.
Cleeremans, Axel, and Zoltán Dienes. 2008. “Computational Models of Implicit Learning.” In The Cambridge Handbook of Computational Psychology, edited by Ron Sun, 396–421. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511816772.018.
Remillard, Gilbert, and James M. Clark. 2001. “Implicit Learning of First-, Second-, and Third-Order Transition Probabilities.” Journal of Experimental Psychology: Learning, Memory, and Cognition 27 (2): 483–98. https://doi.org/10.1037//0278-7393.27.2.483.
Jamieson, Randall K., and D. J. K. Mewhort. 2009. “Applying an Exemplar Model to the Serial Reaction-Time Task: Anticipating from Experience.” Quarterly Journal of Experimental Psychology 62 (9): 1757–83. https://doi.org/10.1080/17470210802557637.